Show the code
# Données
library(ISLR) # Hitters data
library(dplyr) # manipulation des données
# Infrence
library(pls) ## PCR et PLSR
# Plots
## ggplot
library(ggplot2)
library(gridExtra)Dans l’analyse des données et la modélisation statistique, la régression linéaire classique peut être limitée lorsque les variables explicatives sont fortement corrélées (problème de colinéarité) ou lorsque leur nombre est supérieur au nombre d’observations (problème de haute dimensionnalité). Pour remédier à ces défis, des méthodes de réduction de dimensionnalité comme la Régression sur Composantes Principales (PCR) et la Régression des Moindres Carrés Partiels (PLSR) sont utilisées.
La régression sur Composantes Principales (PCR) repose sur une Analyse en Composantes Principales (ACP) pour transformer les variables explicatives en nouvelles variables orthogonales appelées composantes principales. Seules les premières composantes, capturant le plus de variance, sont conservées dans la régression.
Cette approche permet de réduire la multicolinéarité et d’éviter le sur-ajustement en limitant la complexité du modèle.
Cependant, la PCR ne prend pas en compte la relation entre les variables explicatives et la variable réponse lors de la sélection des composantes.
Contrairement à la PCR, la régression des Moindres Carrés Partiels (PLSR) cherche à maximiser la covariance entre les variables explicatives et la variable réponse.
Elle construit des composantes latentes qui capturent non seulement la variance des variables explicatives mais aussi leur corrélation avec la variable à prédire.
Cette méthode est souvent plus efficace que la PCR pour les problèmes de prédiction, car elle optimise directement la relation entre les prédicteurs et la réponse.
En résumé, la PCR est une approche basée sur la variance des prédicteurs, tandis que la PLSR optimise la relation entre les prédicteurs et la réponse.
Le choix entre ces deux méthodes dépend du contexte : la PCR est utile pour la réduction de dimensionnalité, tandis que la PLSR est souvent plus performante pour la prédiction
# Données
library(ISLR) # Hitters data
library(dplyr) # manipulation des données
# Infrence
library(pls) ## PCR et PLSR
# Plots
## ggplot
library(ggplot2)
library(gridExtra)my_validationplot <- function(mod, data) {
msep.cv <- MSEP(mod, estimate = c("CV", "adjCV"))
rmsep.cv <- RMSEP(mod, estimate = c("CV", "adjCV"))
x_msep <- c(msep.cv$val[1, , ], msep.cv$val[2, , ])
x_rmsep <- c(rmsep.cv$val[1, , ], rmsep.cv$val[2, , ])
y <- c(rep("CV", length(msep.cv$val[2, , ])), rep("adjCV", length(msep.cv$val[2, , ])))
z <- c(0:(ncol(data) - 1), 0:(ncol(data) - 1))
dt <- data.frame(x_msep, x_rmsep, y, z)
colnames(dt) <- c("MSEP", "RMSEP", "sample", "comps")
## MSEP
p.msep <- ggplot(dt, aes(x = comps, y = MSEP, col = sample)) +
geom_line() +
theme_bw() +
labs(
title = "Évolution du MSEP en fonction du nombre de composantes",
x = "Nombre de composantes",
y = "RMSEP",
color = "Échantillon"
) +
theme(
plot.title = element_text(size = 16, face = "bold"),
axis.title = element_text(size = 14, face = "bold"),
axis.text = element_text(size = 12),
legend.title = element_text(size = 14, face = "bold"),
legend.text = element_text(size = 12)
)
## RMSEP
p.rmsep <- ggplot(dt, aes(x = comps, y = RMSEP, col = sample)) +
geom_line() +
theme_bw() +
labs(
title = "Évolution du RMSEP en fonction du nombre de composantes",
x = "Nombre de composantes",
y = "RMSEP",
color = "Échantillon"
) +
theme(
plot.title = element_text(size = 16, face = "bold"),
axis.title = element_text(size = 14, face = "bold"),
axis.text = element_text(size = 12),
legend.title = element_text(size = 14, face = "bold"),
legend.text = element_text(size = 12)
)
## Explain variance
explain_variance <- explvar(mod)
# Créer un data frame
dt_var <- data.frame(comps = seq_along(explain_variance),
variance = explain_variance * 100)
# Tracer le graphique
p.variance <- ggplot(dt_var, aes(x = comps, y = variance)) +
geom_line(color = "blue") +
geom_point(color = "red") +
theme_bw() +
labs(title = "Évolution de la Variance Expliquée en Fonction du Nombre de Composantes", x = "Nombre de Composantes", y = "Variance Expliquée (%)") +
theme(
plot.title = element_text(size = 16, face = "bold"),
axis.title = element_text(size = 14, face = "bold"),
axis.text = element_text(size = 12)
)
return(list(MSEP = p.msep, RMSEP = p.rmsep, Exp_Var = p.variance))
}set.seed(140400)On étudie à nouveau le jeu de données Hitters disponible dans la libraire {ISLR} de R. Il s’agit d’un jeu de données de la Major League Baseball provenant des saisons de 1986 et 1987.
Le jeu de données possède 322 lignes/individus pour les différents joueurs et 20 variables.
Parmi les variables, on trouve les informations suivantes :
| AtBat | Number of times at bat in 1986 |
| Hits | Number of hits in 1986 |
| HmRun | Number of home runs in 1986 |
| Runs | Number of runs in 1986 |
| RBI | Number of runs batted in in 1986 |
| Walks | Number of walks in 1986 |
| Years | Number of years in the major leagues |
| CAtBat | Number of times at bat during his career |
| CHits | Number of hits during his career |
| CHmRun | Number of home runs during his career |
| CRuns | Number of runs during his career |
| CRBI | Number of runs batted in during his career |
| CWalks | Number of walks during his career |
| League | A factor with levels A and N indicating player's league at the end of 1986 |
| Division | A factor with levels E and W indicating player's division at the end of 1986 |
| PutOuts | Number of put outs in 1986 |
| Assists | Number of assists in 1986 |
| Errors | Number of errors in 1986 |
| Salary | 1987 annual salary on opening day in thousands of dollars |
| NewLeague | A factor with levels A and N indicating player's league at the beginning of 1987 |
Comme pour l’Exercice 1, on va commencer par se débarasser des variables manquantes.
Hitters_Without_NA <- Hitters %>% na.omit()Comme cela fait maintenant plusieurs fois que l’on fait affaire à ce jeu de données, on se passera des analyses descritpives faites en Exercice 1.
Ainsi, on va pouvoir tout de suite commencer par faire le découpage de notre jeu de données en échantillon train et test. Le jeu de données train contiendra 3/4 des individus sans valeurs manquantes de Hitters, tirés aléatoirement. Le reste du jeu de données composera l’échantillon test.
percent_to_draw <- 0.75
index_train <- sample(nrow(Hitters_Without_NA), size = floor(percent_to_draw * nrow(Hitters_Without_NA)))
Hitters_train <- Hitters_Without_NA[index_train, ]
Hitters_test <- Hitters_Without_NA[-index_train, ]On va maintenant effectuer une régression PCR et une régression PLSR sur l’échantillon train en sélectionnant le nombre de composantes par une validation croisée K-fold où \(K = 10\).
mod_pcr <- pcr(
Salary ~ .,
scale = TRUE,
data = Hitters_train,
validation = "CV",
segments = 10
)
mod_pcr %>% summary()Data: X dimension: 197 19
Y dimension: 197 1
Fit method: svdpc
Number of components considered: 19
VALIDATION: RMSEP
Cross-validated using 10 random segments.
(Intercept) 1 comps 2 comps 3 comps 4 comps 5 comps 6 comps
CV 451.6 359.2 360.4 362.1 358.4 355.4 361.6
adjCV 451.6 358.6 359.6 361.3 357.6 354.6 360.3
7 comps 8 comps 9 comps 10 comps 11 comps 12 comps 13 comps
CV 362.3 367.7 373.1 374.9 376.3 378.2 378.9
adjCV 360.8 365.8 370.9 372.2 373.7 375.4 376.0
14 comps 15 comps 16 comps 17 comps 18 comps 19 comps
CV 372.9 375.5 352 350.3 349.2 349.8
adjCV 369.6 372.2 349 347.1 345.9 346.4
TRAINING: % variance explained
1 comps 2 comps 3 comps 4 comps 5 comps 6 comps 7 comps 8 comps
X 38.57 60.46 71.0 79.17 84.43 88.90 92.26 95.1
Salary 39.51 40.48 40.6 42.04 43.04 44.32 45.36 45.8
9 comps 10 comps 11 comps 12 comps 13 comps 14 comps 15 comps
X 96.48 97.43 98.12 98.70 99.18 99.5 99.75
Salary 45.81 47.70 47.71 48.14 48.26 51.2 51.55
16 comps 17 comps 18 comps 19 comps
X 99.91 99.97 99.99 100.00
Salary 57.09 58.10 58.89 59.19mod_pls <- plsr(
Salary ~ .,
scale = TRUE,
data = Hitters_train,
validation = "CV",
segments = 10
)
mod_pls %>% summary()Data: X dimension: 197 19
Y dimension: 197 1
Fit method: kernelpls
Number of components considered: 19
VALIDATION: RMSEP
Cross-validated using 10 random segments.
(Intercept) 1 comps 2 comps 3 comps 4 comps 5 comps 6 comps
CV 451.6 353.8 354.0 355.4 354.6 358.6 354.5
adjCV 451.6 353.3 353.1 354.5 353.0 355.7 351.3
7 comps 8 comps 9 comps 10 comps 11 comps 12 comps 13 comps
CV 346.0 338.3 336.1 337.5 335.9 332.6 332.7
adjCV 343.4 336.0 333.7 335.2 333.3 330.3 330.4
14 comps 15 comps 16 comps 17 comps 18 comps 19 comps
CV 329.2 330.3 331.1 329.8 329.1 329.4
adjCV 327.1 328.1 328.7 327.6 326.9 327.2
TRAINING: % variance explained
1 comps 2 comps 3 comps 4 comps 5 comps 6 comps 7 comps 8 comps
X 38.35 51.49 65.93 72.1 76.66 83.61 87.75 89.94
Salary 41.91 45.71 47.66 49.8 52.71 54.18 55.37 56.92
9 comps 10 comps 11 comps 12 comps 13 comps 14 comps 15 comps
X 93.10 95.65 96.66 97.49 98.39 98.58 99.05
Salary 57.52 57.78 58.24 58.40 58.52 58.81 58.88
16 comps 17 comps 18 comps 19 comps
X 99.41 99.74 99.99 100.00
Salary 58.97 59.05 59.09 59.19On peut maintenant visualiser l’évolution du MSEP et RMSEP en fonction du nombre de composantes gardées.
Pour des raisons esthétiques, on à ici construit un graphique à partir de ggplot2mais on aurait pu se contenter d’utiliser la fonction validationplot de la library pls.
grid.arrange(my_validationplot(mod_pcr, Hitters_train)$RMSEP,
my_validationplot(mod_pcr, Hitters_train)$Exp_Var,
ncol=2)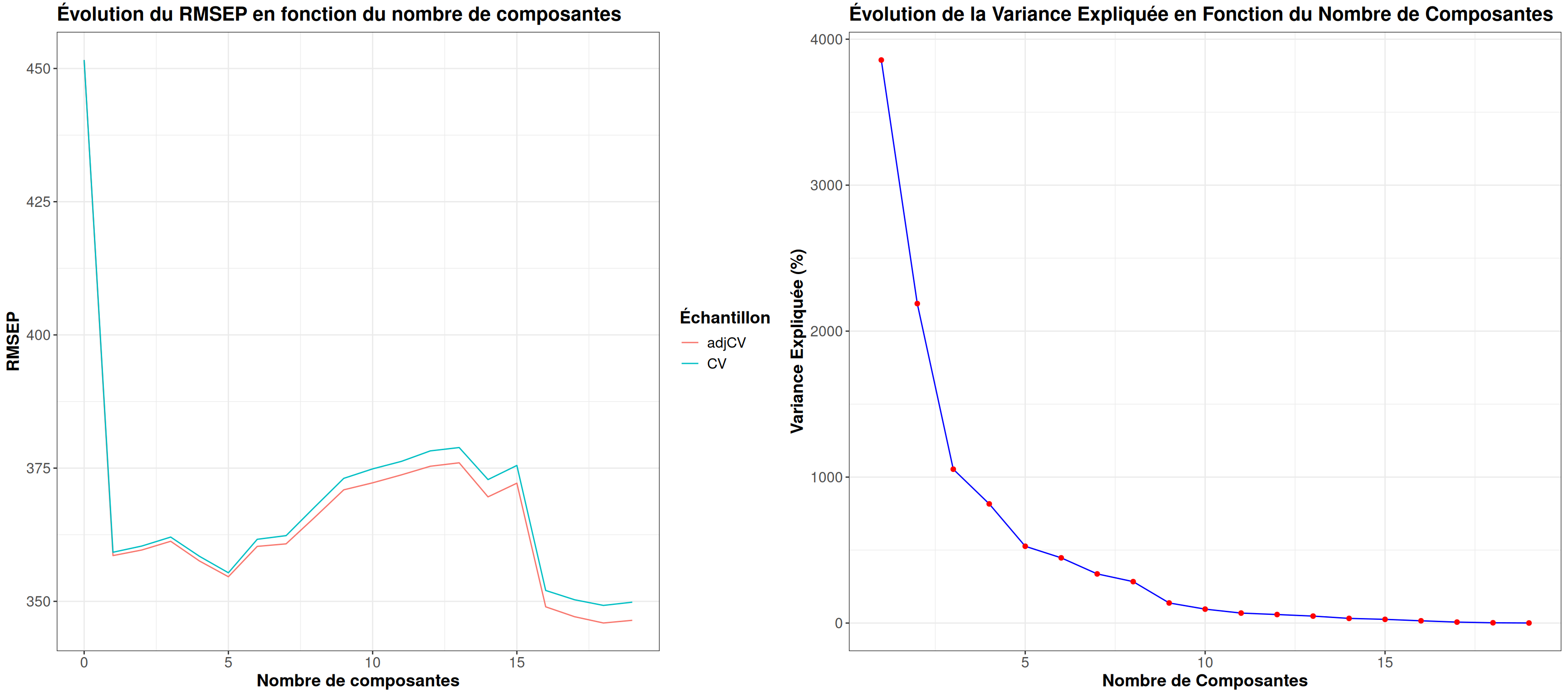
grid.arrange(my_validationplot(mod_pls, Hitters_train)$RMSEP,
my_validationplot(mod_pls, Hitters_train)$Exp_Var,
ncol=2)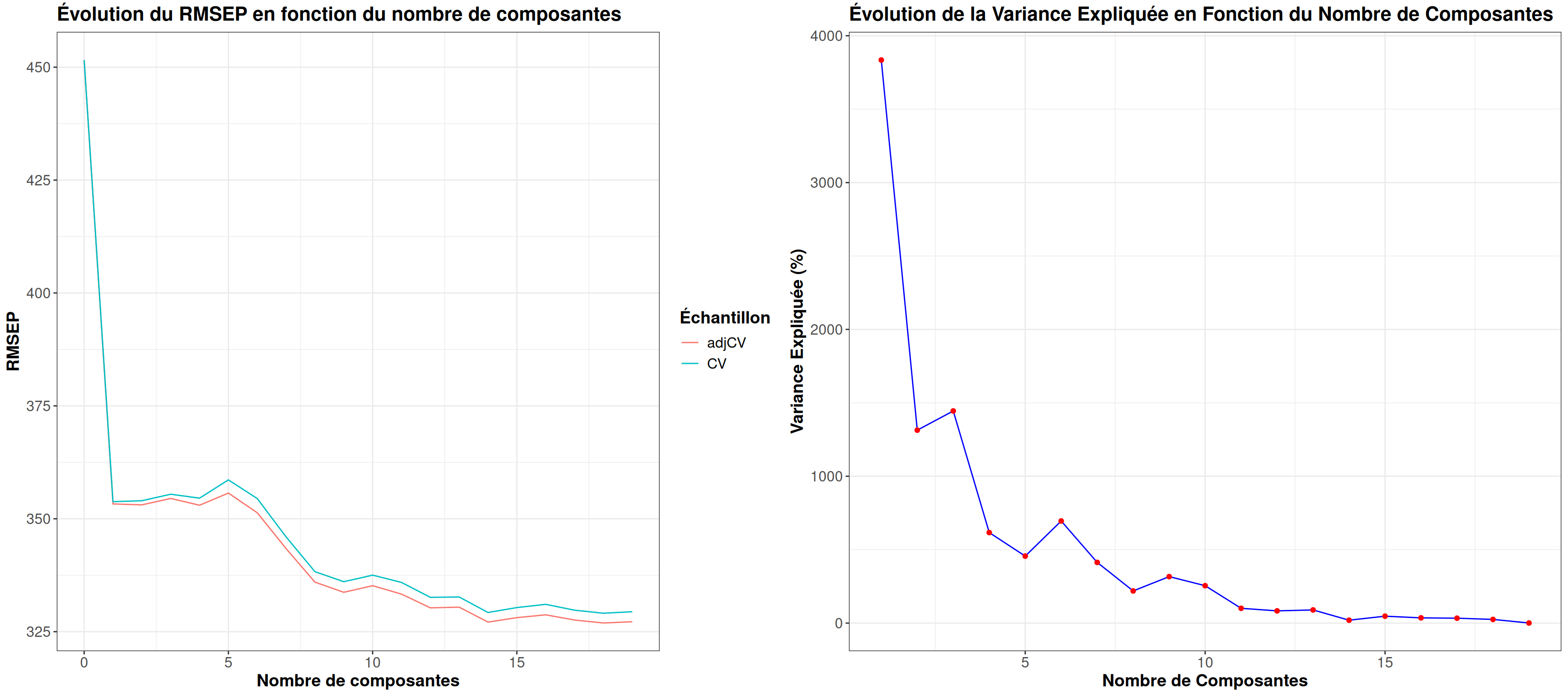
Résultats
Pour la PCR on peut voir courbe proche entre CV et adjCV avec une première valeur minimum qui semble se trouver à partir de 5 composantes.
Ensuite la courbe remonte à nouveau pour redescendre progressivement. Et concernant le pourcentage de variance expliquée, on voit un coude au niveau de 5 composantes.
Tandus que pour la PLSR on voit plutôt que c’est à partir de 5 composantes que la décroissance commence. Et pour le pourcentage de variance expliquée, on voit un coude au niveau de 5 composantes.
Et on peut alors récupérer le nombre de composantes à garder qui minimsent le MSEP et RMSEP.
ncomp.rmsep_pcr <- which.min(RMSEP(mod_pcr, estimate = c("CV"))$val["CV",,])-1
ncomp.rmsep_pls <- which.min(RMSEP(mod_pls, estimate = c("CV"))$val["CV",,])-1Résultats
On a que le nombre de composante à retenir est de 18 pour la PCR et 18 pour la PLSR.
On va calculer le RMSEP calculé à partir de la prédiction pour l’échantillon test.
hat_Hitters_test_mod_pcr <- predict(mod_pcr,
Hitters_test,
ncomp = (which.min(RMSEP(mod_pcr, estimate = c("CV"))$val["CV", , ]) - 1))
rmsep_mod_pcr_pred <- sqrt(mean((hat_Hitters_test_mod_pcr - Hitters_test$Salary) ** 2))
hat_df_test_salary.pls <- predict(mod_pls,
Hitters_test,
ncomp = (which.min(RMSEP(mod_pls, estimate = c("CV"))$val["CV", , ]) - 1))
rmsep_mod_pls_pred <- sqrt(mean((hat_df_test_salary.pls - Hitters_test$Salary) ** 2))rmsep_pred_df <- data.frame("prediction PCR" = rmsep_mod_pcr_pred, "prediction PLS" = rmsep_mod_pls_pred)
rownames(rmsep_pred_df) <- "RMSEP"
rmsep_pred_df prediction.PCR prediction.PLS
RMSEP 369.5149 373.6123Le choix final du modèle peut ainsi se reposer sur celui qui minimise la RMSEP pour la prediction de notre échantillon test.
En conclusion, on a ici 2 méthodes complémentaires permettant de construire des modèles linéaires pour des données de grandes dimension.
Ce sont des méthodes intuitives et robustes souvent utilisés par les statisticiens.
sessioninfo::session_info(pkgs = "attached")─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.4.2 (2024-10-31)
os Ubuntu 24.04.1 LTS
system x86_64, linux-gnu
ui X11
language (EN)
collate fr_FR.UTF-8
ctype fr_FR.UTF-8
tz Europe/Paris
date 2025-02-25
pandoc 3.2 @ /usr/lib/rstudio/resources/app/bin/quarto/bin/tools/x86_64/ (via rmarkdown)
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
dplyr * 1.1.4 2023-11-17 [1] CRAN (R 4.4.2)
forcats * 1.0.0 2023-01-29 [1] CRAN (R 4.4.2)
ggplot2 * 3.5.1 2024-04-23 [1] CRAN (R 4.4.2)
gridExtra * 2.3 2017-09-09 [1] CRAN (R 4.4.2)
ISLR * 1.4 2021-09-15 [1] CRAN (R 4.4.2)
kableExtra * 1.4.0 2024-01-24 [1] CRAN (R 4.4.2)
lubridate * 1.9.4 2024-12-08 [1] CRAN (R 4.4.2)
pls * 2.8-5 2024-09-15 [1] CRAN (R 4.4.2)
purrr * 1.0.2 2023-08-10 [2] CRAN (R 4.3.3)
readr * 2.1.5 2024-01-10 [1] CRAN (R 4.4.2)
stringr * 1.5.1 2023-11-14 [2] CRAN (R 4.3.3)
tibble * 3.2.1 2023-03-20 [2] CRAN (R 4.3.3)
tidyr * 1.3.1 2024-01-24 [1] CRAN (R 4.4.2)
tidyverse * 2.0.0 2023-02-22 [1] CRAN (R 4.4.2)
[1] /home/clement/R/x86_64-pc-linux-gnu-library/4.4
[2] /usr/local/lib/R/site-library
[3] /usr/lib/R/site-library
[4] /usr/lib/R/library
──────────────────────────────────────────────────────────────────────────────