Show the code
# Données
library(ISLR) # Hitters data
library(dplyr) # manipulation des données
# Inférence
library(leaps) # regsubsets
library(car) # pour VIF
# Plots
## ggplot
library(ggplot2)
library(gridExtra)# Données
library(ISLR) # Hitters data
library(dplyr) # manipulation des données
# Inférence
library(leaps) # regsubsets
library(car) # pour VIF
# Plots
## ggplot
library(ggplot2)
library(gridExtra)my_boxplot <- function(data) {
# Transformer les données en format long pour ggplot
data_long <- reshape2::melt(data)
ggplot(data_long, aes(x = variable, y = value, fill = variable)) +
geom_boxplot() +
scale_fill_viridis_d() + # Palette de couleurs harmonieuse
labs(title = "Distribution des Variables (Boxplot)", x = "Variables", y = "Valeurs") +
theme_minimal() + # Thème épuré
theme(axis.text.x = element_text(angle = 45, hjust = 1)) # Rotation des étiquettes
}my_barplot <- function(data, variable1, variable2) {
ggplot(data, aes(x = {{ variable1 }}, fill = {{ variable2 }})) +
geom_bar(position = "dodge") +
scale_fill_manual(values = c("#C41E3A", "#0033A0")) +
labs(
title = "Répartition des joueurs par ligue et division",
x = deparse(substitute(variable1)),
y = "Nombre de joueurs"
) +
theme_minimal()
}my_League_heatmap <- function(data) {
table_league <- as.data.frame(table(
data$League,
data$NewLeague
))
colnames(table_league) <- c("League", "NewLeague", "Count")
ggplot(table_league, aes(x = League, y = NewLeague, fill = Count)) +
geom_tile(color = "white") +
scale_fill_gradient(low = "deeppink", high = "deeppink4") +
geom_text(aes(label = Count), color = "white", size = 5) +
labs(
title = "Transition des Joueurs entre les Ligues",
x = "Ligue d'origine",
y = "Nouvelle Ligue",
fill = "Nombre de joueurs"
) +
theme_minimal()
}my_pairs.panels <- function(data) {
psych::pairs.panels(
data,
method = "pearson", # Méthode de corrélation
hist.col = RColorBrewer::brewer.pal(9, "Set3"), # Couleurs des histogrammes
density = TRUE, # Ajout des courbes de densité
ellipses = TRUE, # Ajout d'ellipses
smooth = TRUE, # Ajout de régressions lissées
lm = TRUE, # Ajout des droites de régression
col = "#69b3a2",
alpha = 0.5, # Transparence
cex.labels = 3.5, # Taille du texte des variables
font.labels = 2 # Mettre en gras
)
}my_VIFplot <- function(vif) {
vif_df <- data.frame(Variable = names(vif), VIF = vif)
p <- ggplot(vif_df, aes(
x = reorder(Variable, VIF),
y = pmin(VIF, 15),
fill = VIF > 10
)) +
geom_bar(stat = "identity") +
geom_text(aes(label = ifelse(VIF > 10, round(VIF, 1), "")), hjust = -0.2, size = 6) +
coord_flip() +
scale_fill_manual(values = c("FALSE" = "#0072B2", "TRUE" = "#D55E00")) +
labs(title = "Variance Inflation Factor (VIF)", x = "Variables", y = "VIF (limité à 15)") +
theme_minimal() +
theme(
axis.title = element_text(size = 34, face = "bold"),
plot.title = element_text(
size = 54,
face = "bold",
hjust = 0.5
),
axis.text.x = element_text(size = 26),
axis.text.y = element_text(size = 18),
legend.text = element_text(size = 30),
legend.title = element_text(size = 38, face = "bold")
)
return(p)
}On rappel que \(SCR = \sum_i (y_i - f(x_i))^2\) et \(SCT = \sum_i (y_i - \bar{y})^2\).
Ainsi, on peut trouver les différents critères :
\[ R^2 = 1 - \frac{SCR}{SCT}\]
r2_fun <- function(y, SCR){
# r2 = SSE/SST = (SST - SSR)/SST = 1 - ssr/sst
SCT <- sum((y - mean(y) )^2)
r2 <- 1 - SCR/SCT
return(r2)
}\[ R^2_{adjusted} = 1 - \frac{SCR (n-1)}{SCT(n-(p+1))}\]
r2a_fun <- function(y, SCR){
n <- dim(Hitters_Without_NA)[1]
p <- 1:(dim(Hitters_Without_NA)[2]-1)
SCT <- sum((y - mean(y) )^2)
r2a <- 1 - (SCR/(n-(p+1)))/(SCT/(n-1))
return(r2a)
}\[ C_p = \frac{SCR}{\sigma^2} + 2(p+1) - n\]
cp_fun <- function(mod, SCR){
sig <- summary(mod)$sigma
n <- dim(Hitters_Without_NA)[1]
p <- 1:(dim(Hitters_Without_NA)[2]-1)
cp <- SCR/sig^2 + 2*(p+1) - n
return(cp)
}\[ AIC = n\text{log}\left(\frac{SCR}{n}\right) + 2(p+1)\]
aic_fun <- function(SCR){
n <- dim(Hitters_Without_NA)[1]
p <- 1:(dim(Hitters_Without_NA)[2]-1)
aic <- n * log(SCR/n) + 2*(p+1)
return(aic)
}\[ BIC = n\text{log}\left(\frac{SCR}{n}\right) + \text{log}(n)(p+1)\]
bic_fun <- function(SCR){
n <- dim(Hitters_Without_NA)[1]
p <- 1:(dim(Hitters_Without_NA)[2]-1)
bic <- n * log(SCR/n) + log(n)*(p+1)
return(bic)
}Criteria_plot <- function(Criteria, crit_name = "Critère") {
# Création d'un data frame pour ggplot
df_criteria <- data.frame(
nb_var = seq_along(Criteria), # Nombre de variables du modèle
Criteria = Criteria # Critère
)
# Création du plot avec ggplot2
g <- ggplot(df_criteria, aes(x = nb_var, y = Criteria)) +
geom_line(color = "#0072B2", linewidth = 1) +
geom_point(color = "#D55E00", size = 4) +
labs(
title = paste("Évolution de", crit_name, "en fonction du nombre de variables"),
x = "Nombre de variables sélectionnées",
y = crit_name
) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 26), # Titre centré et agrandi
axis.title.x = element_text(face = "bold", size = 22),
axis.title.y = element_text(face = "bold", size = 22),
axis.text = element_text(size = 20)
)
return(g)
}Best_model <- function(model, criteria_df){
## On a d'abord les critères à maximiser
for(i in 1:2){
criteria_name <- colnames(criteria_df)[i]
criteria <- criteria_df[,i]
best_model_criteria <- which.max(criteria)
selected_vars <- summary(model)$which[best_model_criteria,]
cat("Meilleur modèle selon", criteria_name, " = ", round(max(criteria), 3), " : Modèle avec", best_model_criteria, "variables\n",
rownames(as.data.frame(selected_vars)[as.data.frame(selected_vars)[, 1] == TRUE, , drop = FALSE]), "\n", "\n")
}
## On a ensuite les critères à minimiser
for(i in 3:5){
criteria_name <- colnames(criteria_df)[i]
criteria <- criteria_df[,i]
best_model_criteria <- which.min(criteria)
selected_vars <- summary(model)$which[best_model_criteria,]
cat("Meilleur modèle selon", criteria_name, " = ", round(min(criteria), 3)," : Modèle avec", best_model_criteria, "variables\n",
rownames(as.data.frame(selected_vars)[as.data.frame(selected_vars)[, 1] == TRUE, , drop = FALSE]), "\n", "\n")
}
}On étudie le jeu de données Hitters disponible dans la libraire {ISLR} de R. Il s’agit d’un jeu de données de la Major League Baseball provenant des saisons de 1986 et 1987.
Le jeu de données possède 322 lignes/individus pour les différents joueurs et 20 variables.
Parmi les variables, on trouve les informations suivantes :
| AtBat | Number of times at bat in 1986 |
| Hits | Number of hits in 1986 |
| HmRun | Number of home runs in 1986 |
| Runs | Number of runs in 1986 |
| RBI | Number of runs batted in in 1986 |
| Walks | Number of walks in 1986 |
| Years | Number of years in the major leagues |
| CAtBat | Number of times at bat during his career |
| CHits | Number of hits during his career |
| CHmRun | Number of home runs during his career |
| CRuns | Number of runs during his career |
| CRBI | Number of runs batted in during his career |
| CWalks | Number of walks during his career |
| League | A factor with levels A and N indicating player's league at the end of 1986 |
| Division | A factor with levels E and W indicating player's division at the end of 1986 |
| PutOuts | Number of put outs in 1986 |
| Assists | Number of assists in 1986 |
| Errors | Number of errors in 1986 |
| Salary | 1987 annual salary on opening day in thousands of dollars |
| NewLeague | A factor with levels A and N indicating player's league at the beginning of 1987 |
Regardons maintenant le summary pour examiner les différentes variables.
# ?Hitters
Hitters %>%
summary() AtBat Hits HmRun Runs
Min. : 16.0 Min. : 1 Min. : 0.00 Min. : 0.00
1st Qu.:255.2 1st Qu.: 64 1st Qu.: 4.00 1st Qu.: 30.25
Median :379.5 Median : 96 Median : 8.00 Median : 48.00
Mean :380.9 Mean :101 Mean :10.77 Mean : 50.91
3rd Qu.:512.0 3rd Qu.:137 3rd Qu.:16.00 3rd Qu.: 69.00
Max. :687.0 Max. :238 Max. :40.00 Max. :130.00
RBI Walks Years CAtBat
Min. : 0.00 Min. : 0.00 Min. : 1.000 Min. : 19.0
1st Qu.: 28.00 1st Qu.: 22.00 1st Qu.: 4.000 1st Qu.: 816.8
Median : 44.00 Median : 35.00 Median : 6.000 Median : 1928.0
Mean : 48.03 Mean : 38.74 Mean : 7.444 Mean : 2648.7
3rd Qu.: 64.75 3rd Qu.: 53.00 3rd Qu.:11.000 3rd Qu.: 3924.2
Max. :121.00 Max. :105.00 Max. :24.000 Max. :14053.0
CHits CHmRun CRuns CRBI
Min. : 4.0 Min. : 0.00 Min. : 1.0 Min. : 0.00
1st Qu.: 209.0 1st Qu.: 14.00 1st Qu.: 100.2 1st Qu.: 88.75
Median : 508.0 Median : 37.50 Median : 247.0 Median : 220.50
Mean : 717.6 Mean : 69.49 Mean : 358.8 Mean : 330.12
3rd Qu.:1059.2 3rd Qu.: 90.00 3rd Qu.: 526.2 3rd Qu.: 426.25
Max. :4256.0 Max. :548.00 Max. :2165.0 Max. :1659.00
CWalks League Division PutOuts Assists
Min. : 0.00 A:175 E:157 Min. : 0.0 Min. : 0.0
1st Qu.: 67.25 N:147 W:165 1st Qu.: 109.2 1st Qu.: 7.0
Median : 170.50 Median : 212.0 Median : 39.5
Mean : 260.24 Mean : 288.9 Mean :106.9
3rd Qu.: 339.25 3rd Qu.: 325.0 3rd Qu.:166.0
Max. :1566.00 Max. :1378.0 Max. :492.0
Errors Salary NewLeague
Min. : 0.00 Min. : 67.5 A:176
1st Qu.: 3.00 1st Qu.: 190.0 N:146
Median : 6.00 Median : 425.0
Mean : 8.04 Mean : 535.9
3rd Qu.:11.00 3rd Qu.: 750.0
Max. :32.00 Max. :2460.0
NA's :59 On peut déjà remarquer la présence de 59 valeurs manquantes pour la variable Salary.
On va donc commencer par s’en débarasser (il ne s’agit que de 59 joueurs sur les 322).
Puis on va également créer un sous jeu de données ne conservant que les variables quantitatives et un autre conservant les variables qualitatives. Ces jeux de données seront ensuite utilisés dans les analyses descriptives
Hitters_Without_NA <- Hitters %>% na.omit()
Hitters_Without_NA_quant <- Hitters_Without_NA %>% subset(, select = -c(League, Division, NewLeague))
Hitters_Without_NA_quali <- Hitters_Without_NA %>% subset(, select = c(League, Division, NewLeague))Avant de se lancer dans des analyses inférentielles avec de l’estimation, prédiction, etc… Il convient toujours de commencer par quelques analyses descritpives afin de mieux comprendre les données sur lesquelles on travail.
On peut regarder un peu la distribution de nos différentes variables quantitatives via des boxplots.
my_boxplot(Hitters_Without_NA_quant)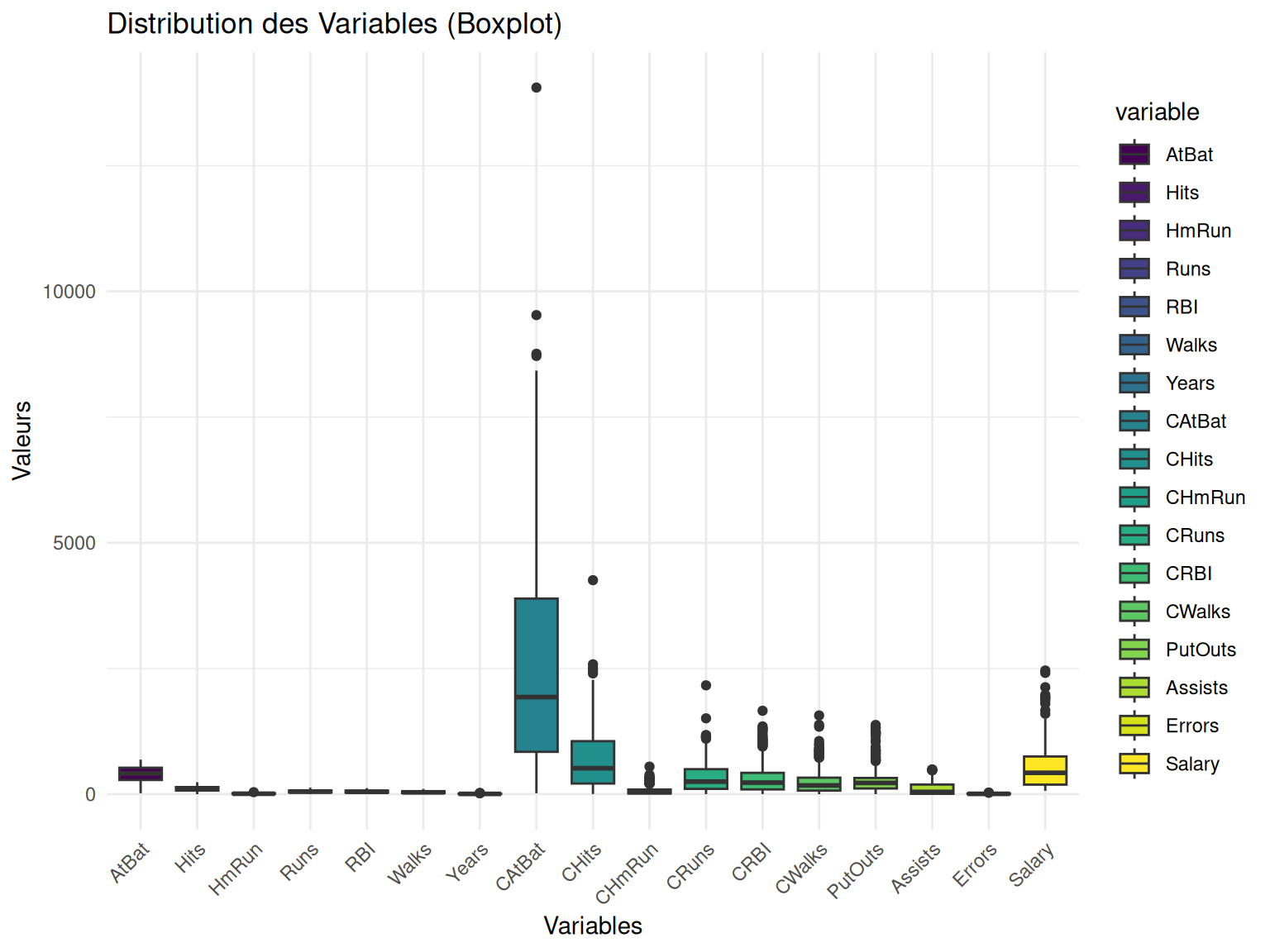
Résultats
Comme on pouvait s’y attendre, on retrouve des distributions assez variées selon les différentes statistques des joueurs.
On peut tout de même remarquer que nos variables ont en général peu de valeurs outliers (valeurs extrêmes par rapport aux autres).
On regarde ici la corrélation calculée entre chacune de nos variables quantitative.
my_pairs.panels(Hitters_Without_NA_quant)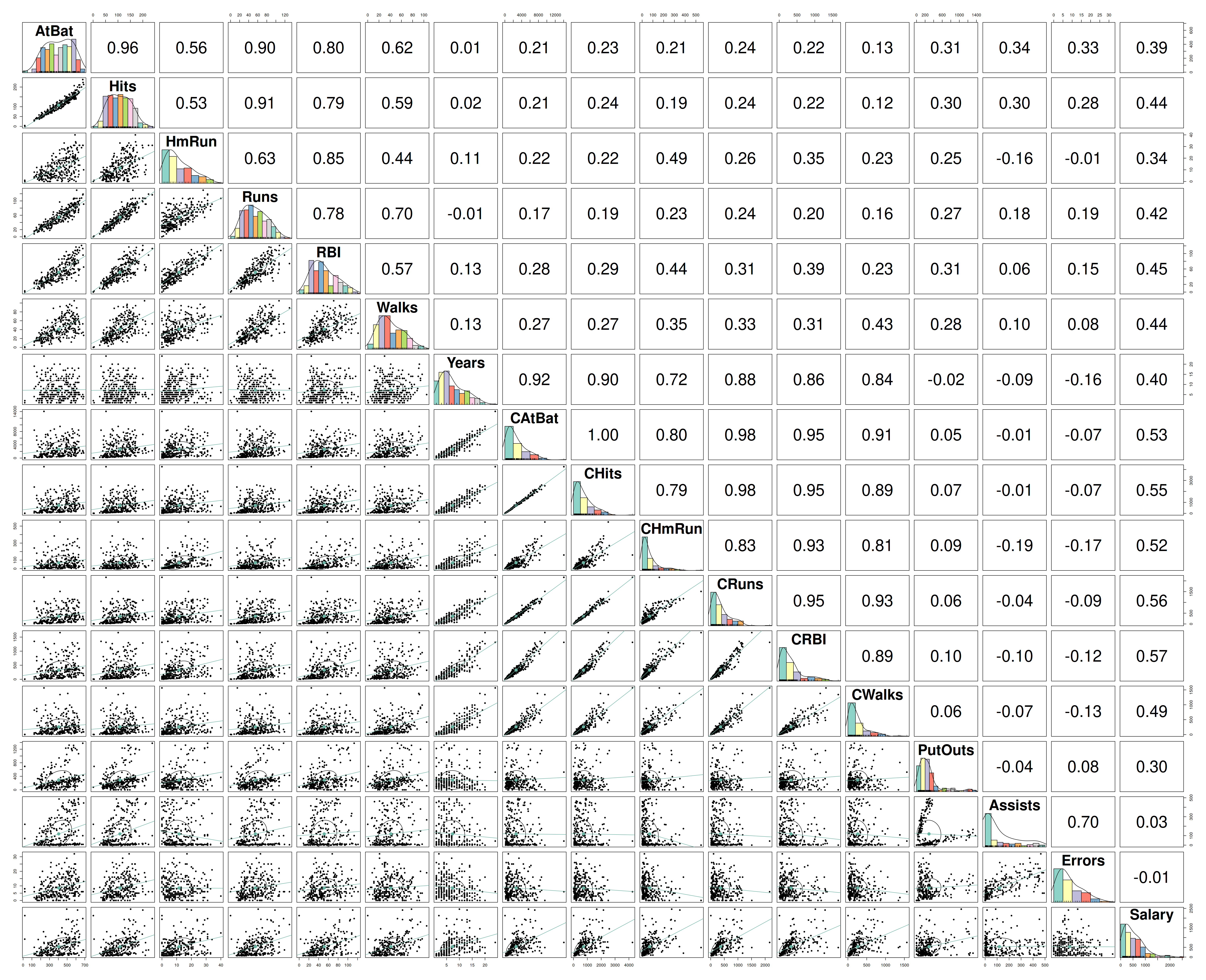
Résultats
On voit la présence de plusieurs fortes corrélations qui peut déjà nous alerter si l’on veut faire des modèles de régressions linéaires car on risque d’avoir un problème de colinéarité entre les varibales explicatives.
Parmi ces fortes corrélations, on arrive même à distiguer deux zones où les variables sont très corrélées entre elles (de AtBat à RBI et de Years à Cwalks)
Par contre, il n’y a aucune forte corrélation entre la variable Salary et les autres variables du jeu de données. Ce qui peut nous indiquer qu’il n’y aura pas une variable avec très forte influence sur Salary.
Ici, regardons un peu le nombre des joueurs par ligue, selon la division. Et on fera cela pour les variables League et NewLeague.
grid.arrange(my_barplot(Hitters_Without_NA_quali, League, Division),
my_barplot(Hitters_Without_NA_quali, NewLeague, Division)
, ncol=2)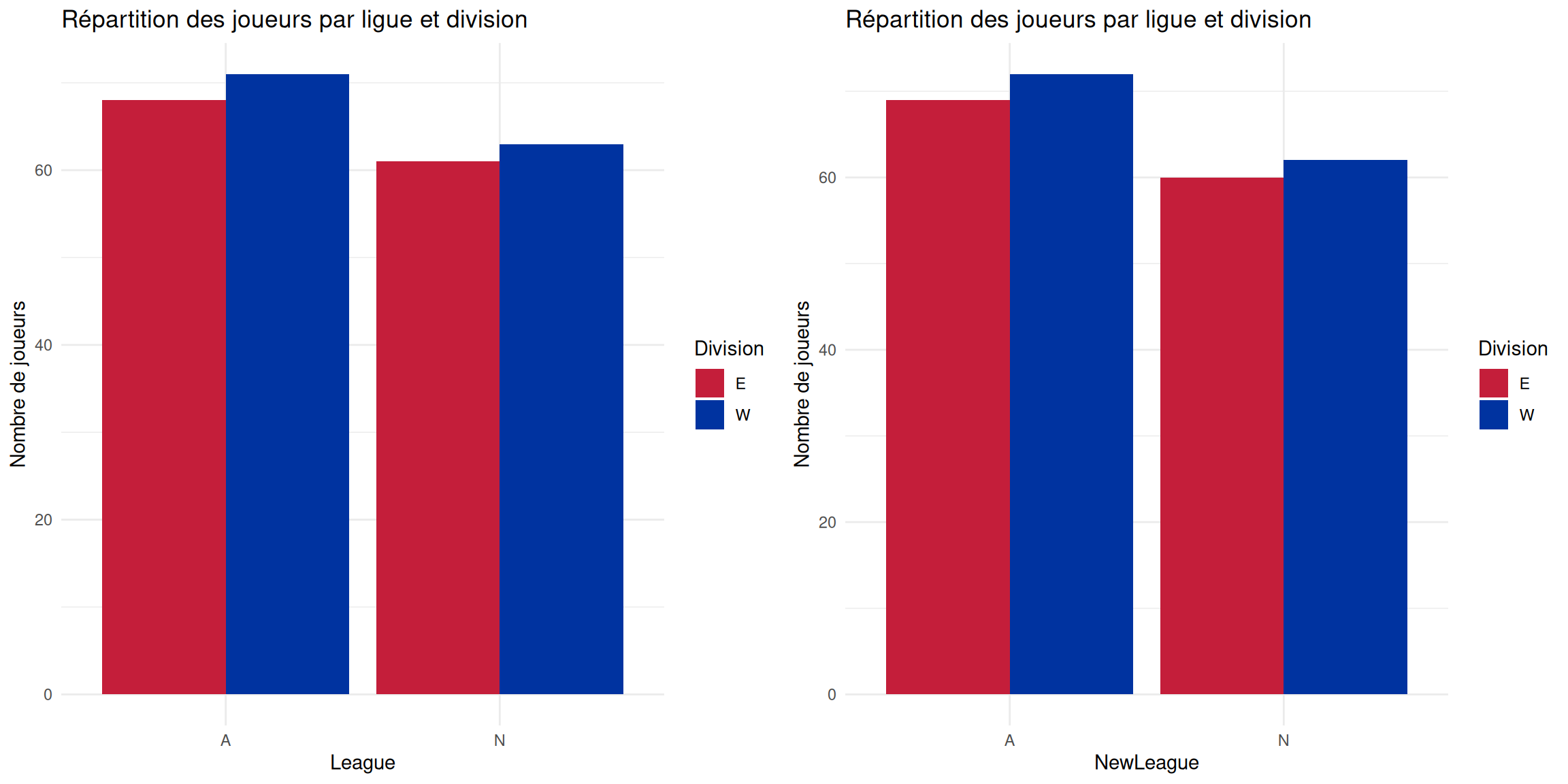
Résultats
De manière globale, on peut remarquer que de fin 1986 à début 1987, il ne semble pas y avoir beaucoup de changement dans la répartition des joueurs par ligue selon la division.
De manière plus locale, on remarque qu’il y a un peu plus de joueur en division Ouest (West) que division Est (East). Et ça, qu’on soit en ligue Américaine (American League) ou ligue Nationale (National League)
On peut regarder la Heatmap nous donnans la transition des joueurs entre les ligues, i.e on regarde la similarité des variables League et NewLeague.
my_League_heatmap(Hitters_Without_NA_quali)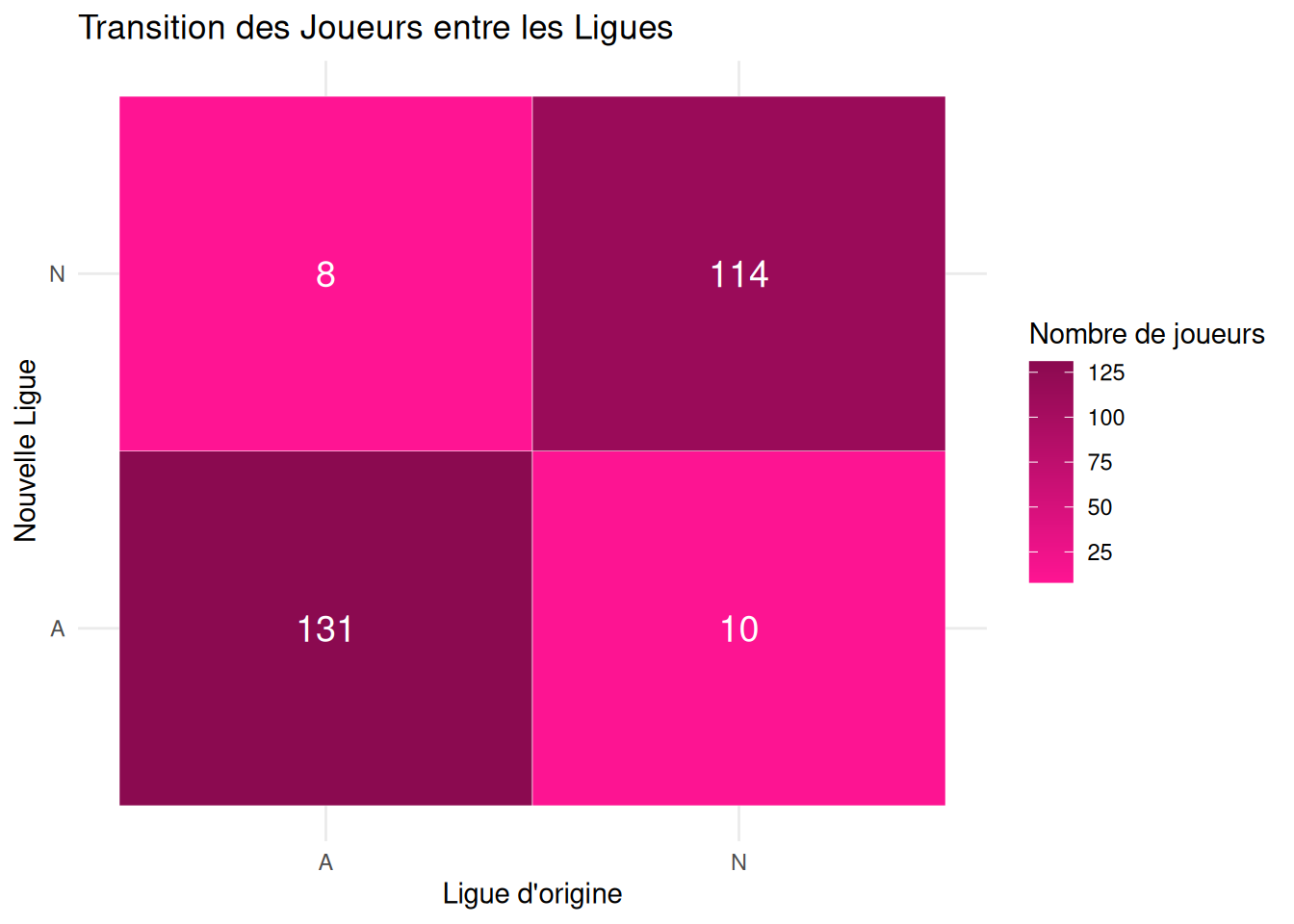
Résultats
On voit bien ici qu’effectivement les joueurs n’ont globalement pas changer de ligue entre fin 1986 et début 1987. Seulement 8 joueurs sont passés de ligue américaine à ligue nationale et 10 de ligue nationale à ligue américaine.
Avec une Analyse en Composantes Principales (PCA) on peut regarder un peu le comportement de nos données.
En effet, Cette méthode respose sur la transformation des variables d’origine en nouvelles variables non corrélées, appelées composantes principales, qui capturent successivement la plus grande variance possible des données.
res_pca <- FactoMineR::PCA(
Hitters_Without_NA,
quali.sup = c(which(
colnames(Hitters_Without_NA) %in% c("League", "Division", "NewLeague")
)),
quanti.sup = which(colnames(Hitters_Without_NA) == "Salary"),
graph = FALSE
)Ici, on spécifi nos variables qualitatives et on décide de mettre la variable Salary en variable supplémentaire, ce qui veut dire qu’elle ne sera pas considéré pour la formation de nos composantes principales (variable que l’on cherchera à estimer plus tard).
Tout d’abord, on peut commencer par regarder le pourcentage de variance expliqué par nos différentes composantes principales.
factoextra::fviz_eig(
res_pca,
ncp = 10,
addlabels = TRUE,
barfill = "coral",
barcolor = "coral",
ylim = c(0, 50),
main = "Percentage of variance of the 10 first components"
)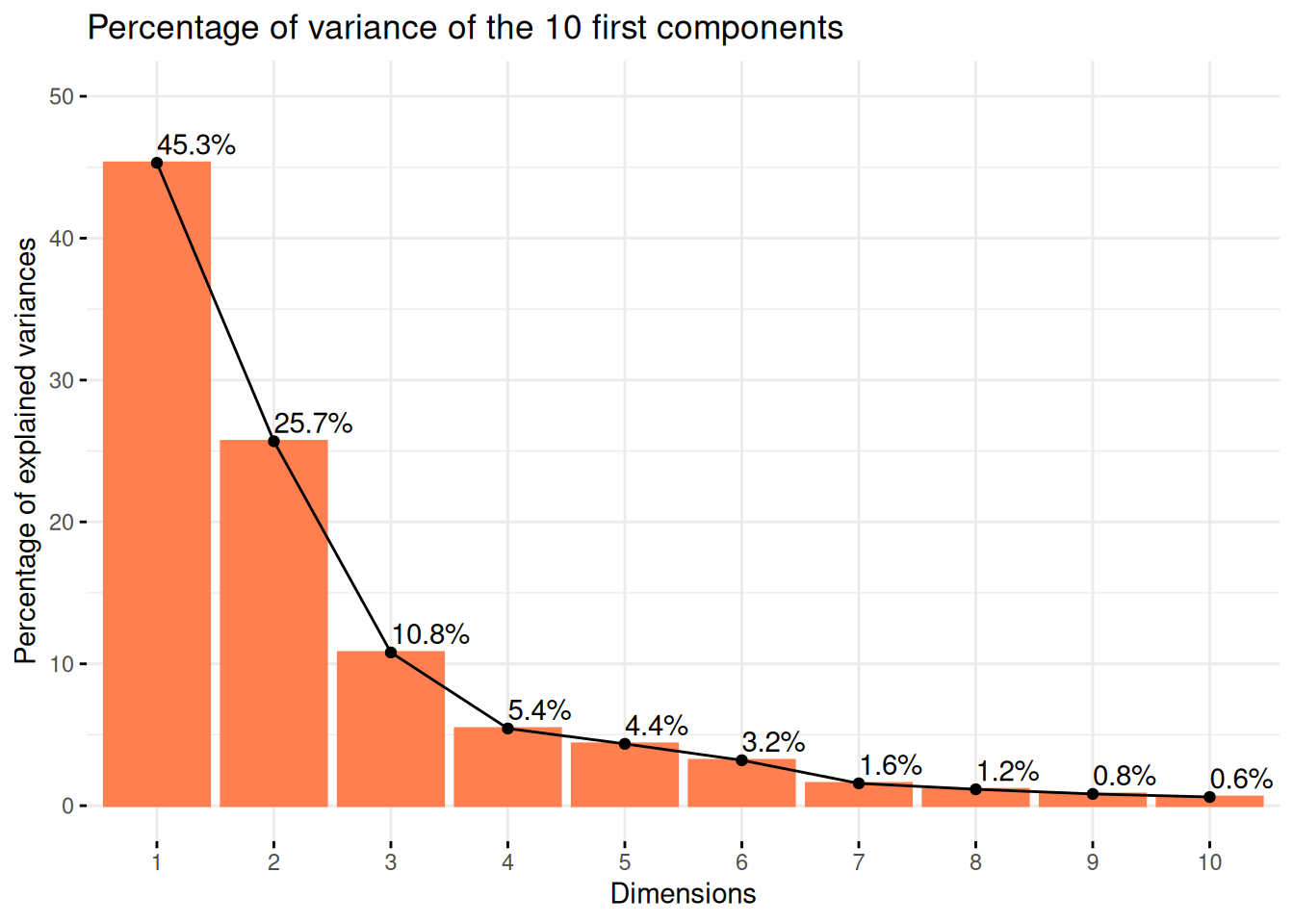
Résultats
On voit ainsi que la majorité de la variance est expliquée par nos deux premières composantes principales avec la présence d’un fort effet de coude après celle-ci.
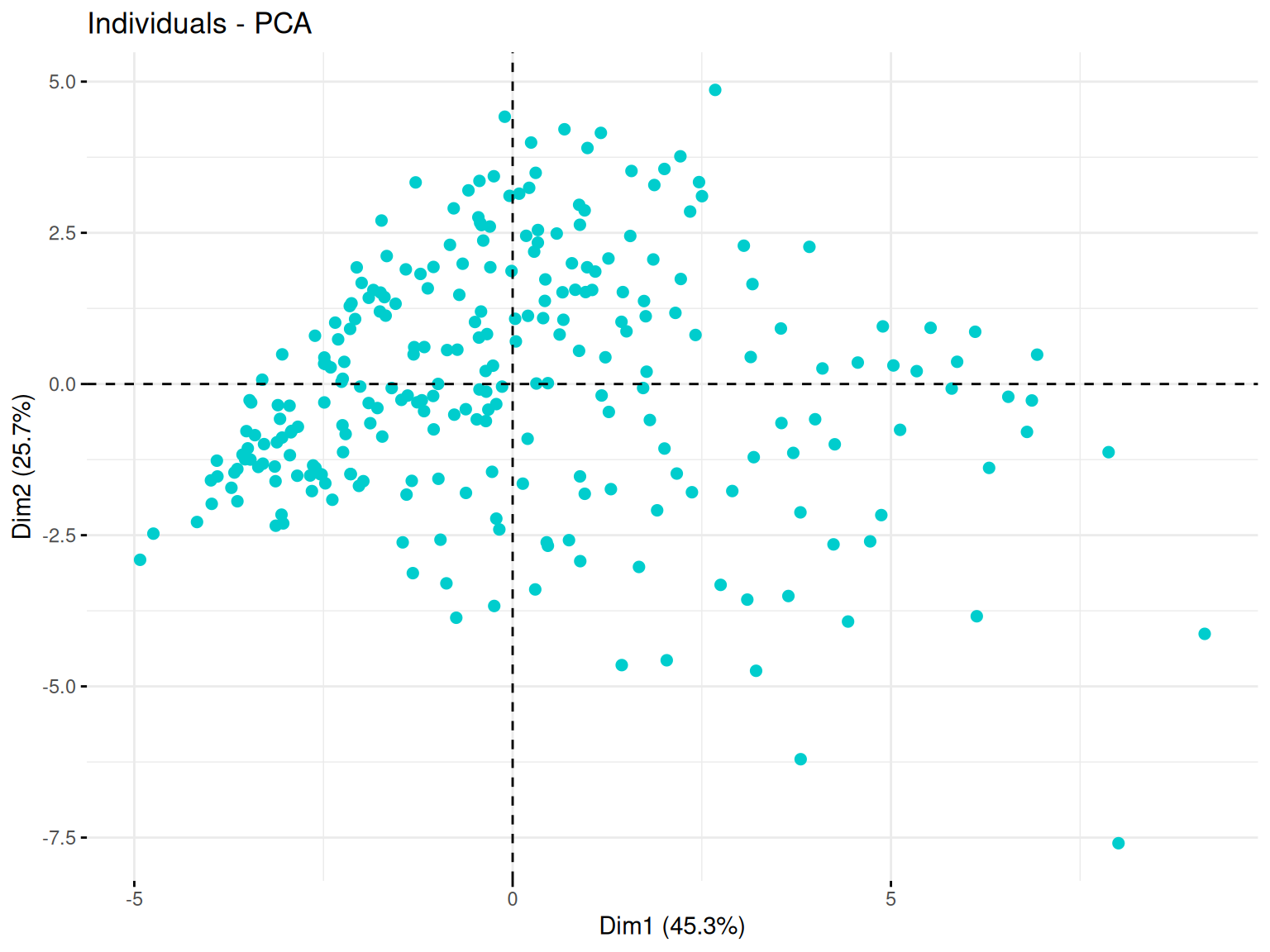
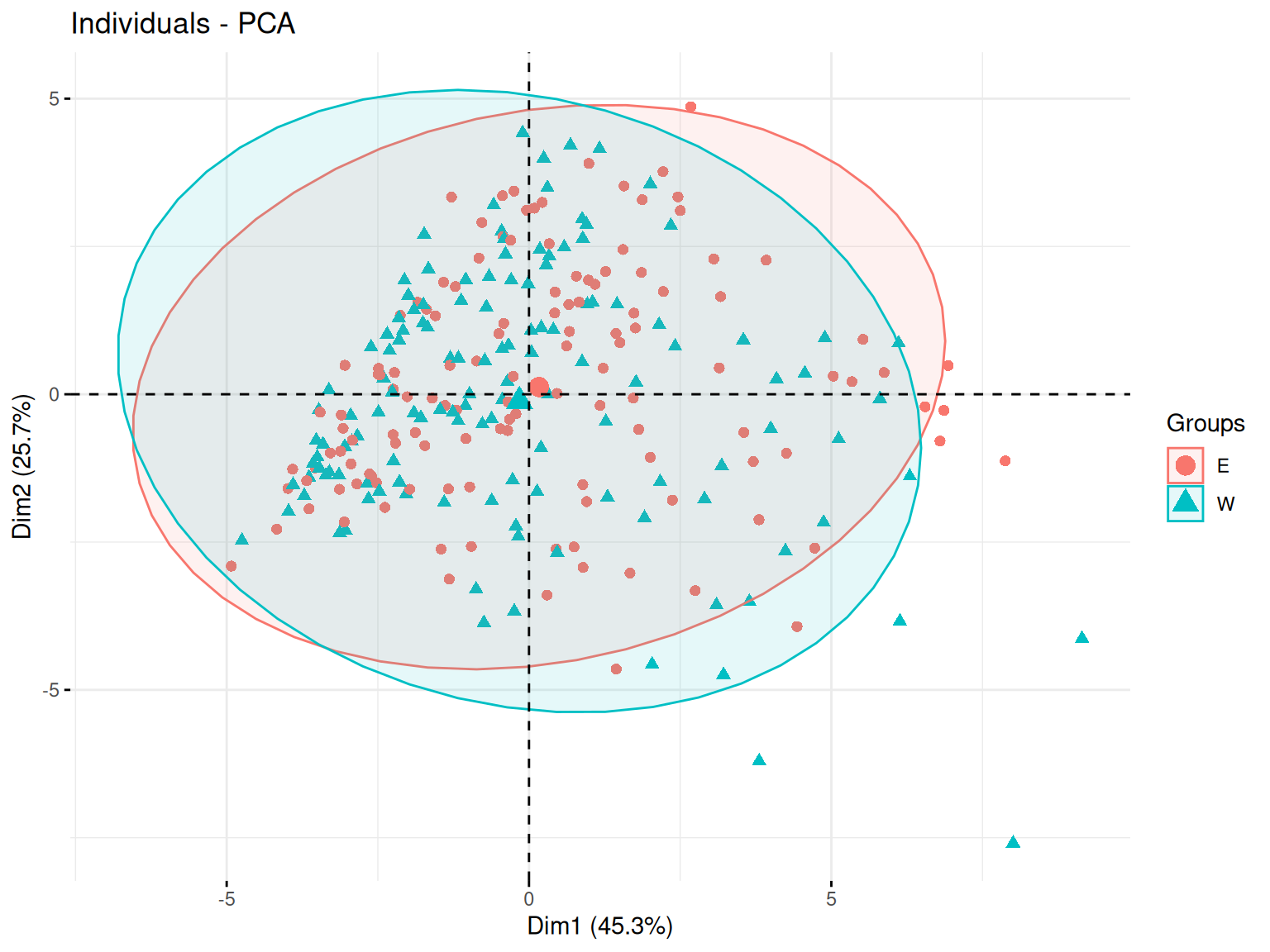
Le plan des individus est une projection des observations (dans notre cas, les joueurs de baseball) sur les axes principaux de la PCA. Cette visualisation permet d’identifier des regroupements, tendances et anomalies au sein des données.
Ainsi, des individus proches sur le graphique ont des caractéristiques similaires par rapport aux variables utilisées.
Puis, le placement d’un individu en fonction des axes peut permettre de savoir comment le jouer se caractérise par rapport aux variables qui contribuent le plus à ces axes.
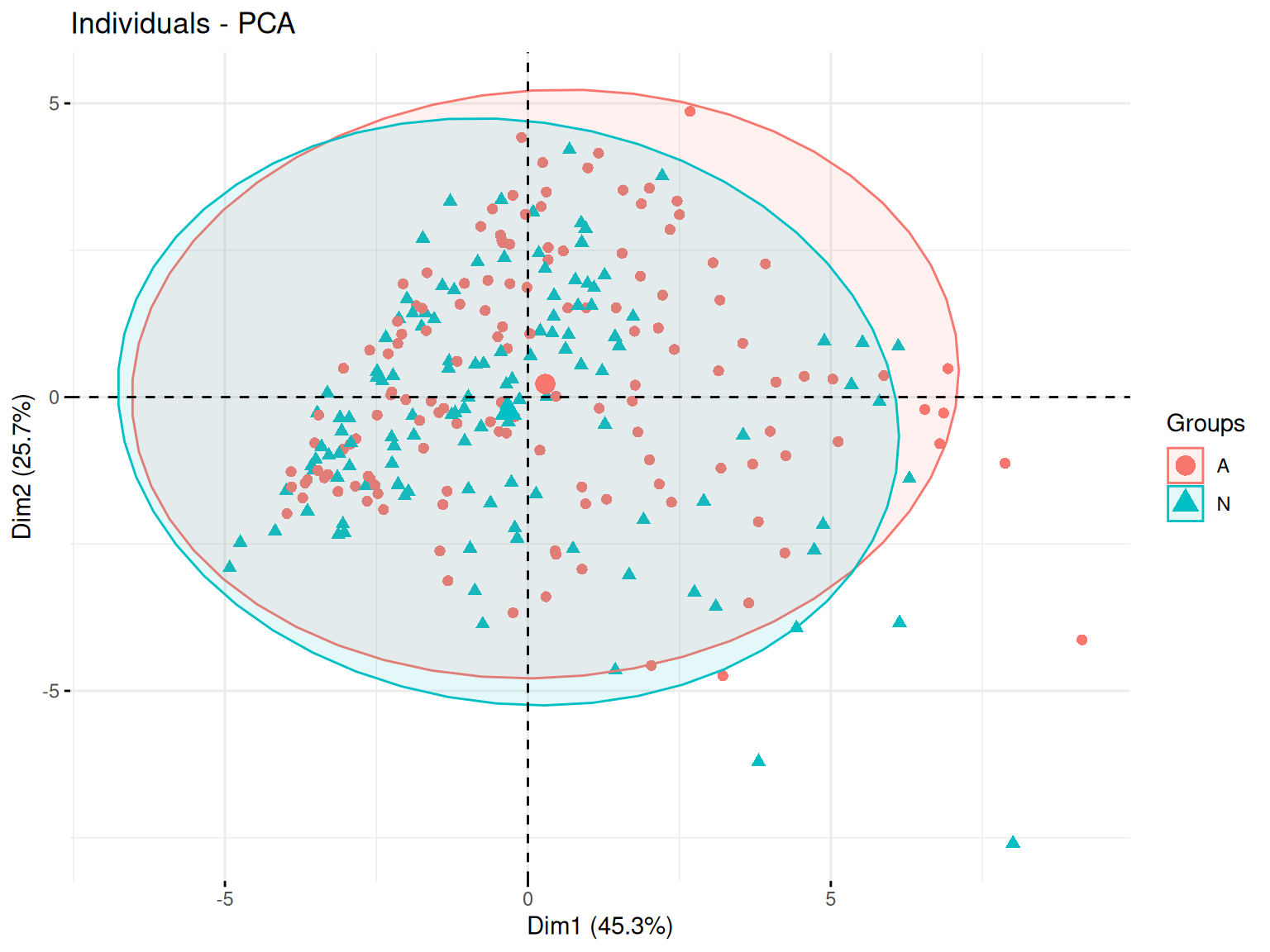
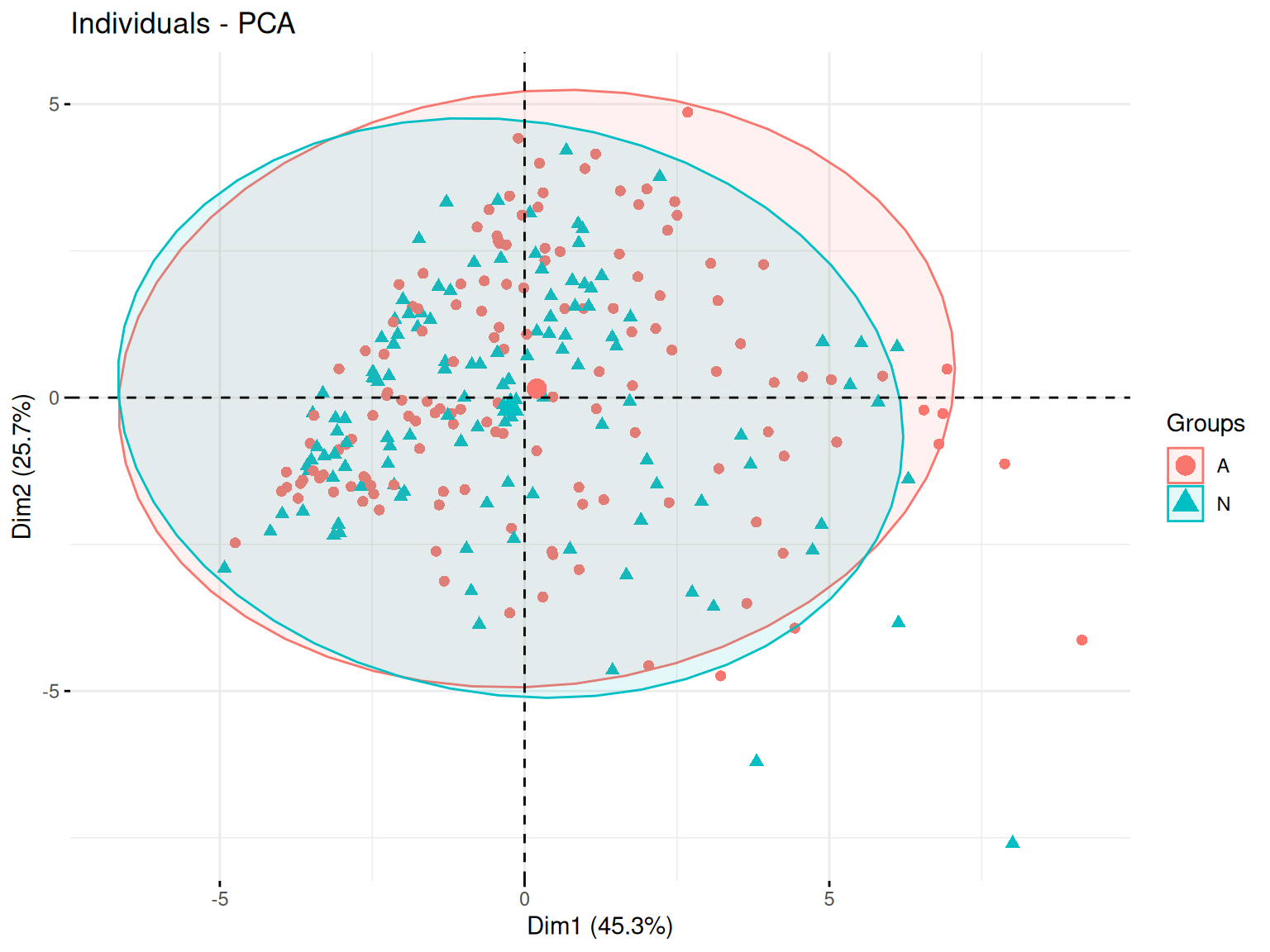
On peut ensuite regarder ce placement en fonction de nos différentes variables qualitatives.
factoextra::fviz_pca_ind(
res_pca,
label = "none",
pointsize = 2,
col.ind = "cyan3"
)
factoextra::fviz_pca_ind(
res_pca,
habillage = Hitters_Without_NA$League,
addEllipses=TRUE,
ellipse.level=0.95,
label = "none",
pointsize = 2,
col.ind = "cyan3"
)
factoextra::fviz_pca_ind(
res_pca,
habillage = Hitters_Without_NA$NewLeague,
addEllipses=TRUE,
ellipse.level=0.95,
label = "none",
pointsize = 2,
col.ind = "cyan3"
)
factoextra::fviz_pca_ind(
res_pca,
habillage = Hitters_Without_NA$Division,
addEllipses=TRUE,
ellipse.level=0.95,
label = "none",
pointsize = 2,
col.ind = "cyan3"
)
Résultats
Ici, on voit que les joueurs se répartissent de manière plûtot uniforme sur le plan ce qui témoignent de la présence d’une grande variété de type de joueurs.
Et on ne voit pas de regroupement se faire en fonction de nos différentes variables qualitatives.
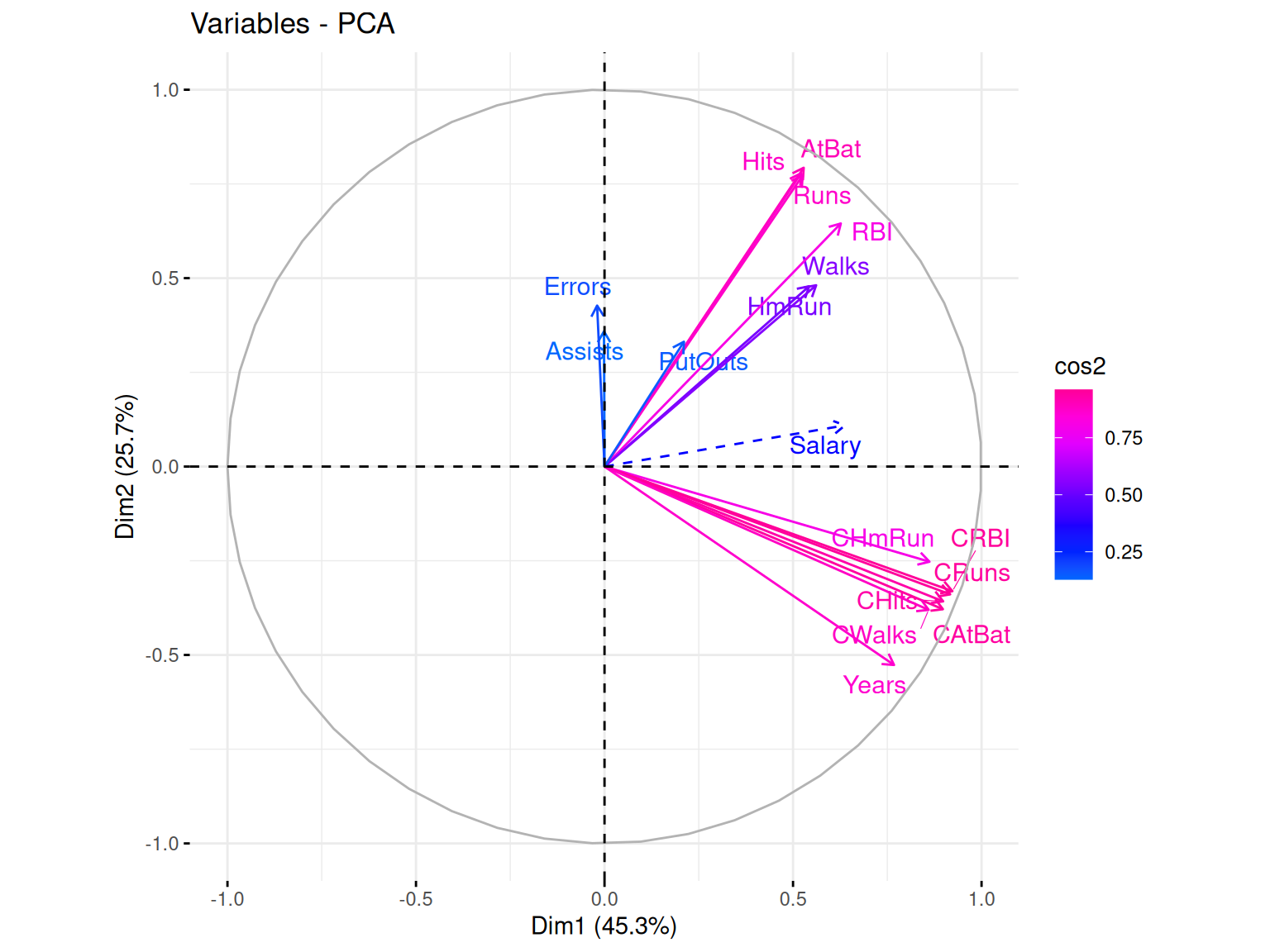
Le cercle des variables est une représentation graphique qui permet d’analyser les relations entre les variables initiales et les composantes principales qui forment nos axes. Il est basé sur les corrélations entre les variables et les axes principaux.
Ainsi, plus une variable est proche du bord du cercle, plus elle est bien représentée sur le plan factoriel et contribue fortement à la formation des axes. Ici, on utilise le cos2 pour le gradient de couleur qui va aider à l’indentifictation de ces différentes qualitées de représentation.
De plus, selon l’angle entre deux varibles, on peut faire des suppositions sur leur corrélation :
Si deux variables ont des vecteurs proches (petit angle), elles sont fortement corrélées positivement
Si deux variables ont des vecteurs opposés (angle proche de 180°), elles sont corrélées négativement
Si l’angle est proche de 90°, alors les variables ne sont pas corrélées
factoextra::fviz_pca_var(
res_pca,
col.var = "cos2",
gradient.cols = rainbow(n = 8, start = .6, end = .9),
repel = TRUE
)
Résultats
Dans notre cas, ce que l’on peut voir c’est que la majorité de nos variables sont bien représentées par nos deux axes (cumulant plus de 70% d’explication). Mais beaucoup semblent aussi fortement corrélées avec la formation de deux groupes et la variable Salary se trouvant au milieu. Cette corrélation entre nos variables quantitatives ayant déjà pu être observé précédemment.
Pour aller un peu plus loin dans la compréhension de ce phénomène, on peut remarquer que les deux groupes correspondent en fait aux variables qui sont des statistiques de joueurs pour la saison de 1986 (Hits, AtBat, Runs, RBI, …) et des statistiques de joueurs sur toute leur carrière (Cwalks, CAtBat, CHmRun, CRBI, …). Ainsi cela explique la présence de fortes corrélations corrélation.
On désire modéliser le salaire Salary en fonction des variables disponibles.
On va donc ajuster un modèle de régression linéaire en utilisant toutes les variables à disposition et analyser la qualité de cet ajustement.
mod1 <- lm(formula = Salary ~ .,
Hitters_Without_NA)
mod1 %>% summary()
Call:
lm(formula = Salary ~ ., data = Hitters_Without_NA)
Residuals:
Min 1Q Median 3Q Max
-907.62 -178.35 -31.11 139.09 1877.04
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 163.10359 90.77854 1.797 0.073622 .
AtBat -1.97987 0.63398 -3.123 0.002008 **
Hits 7.50077 2.37753 3.155 0.001808 **
HmRun 4.33088 6.20145 0.698 0.485616
Runs -2.37621 2.98076 -0.797 0.426122
RBI -1.04496 2.60088 -0.402 0.688204
Walks 6.23129 1.82850 3.408 0.000766 ***
Years -3.48905 12.41219 -0.281 0.778874
CAtBat -0.17134 0.13524 -1.267 0.206380
CHits 0.13399 0.67455 0.199 0.842713
CHmRun -0.17286 1.61724 -0.107 0.914967
CRuns 1.45430 0.75046 1.938 0.053795 .
CRBI 0.80771 0.69262 1.166 0.244691
CWalks -0.81157 0.32808 -2.474 0.014057 *
LeagueN 62.59942 79.26140 0.790 0.430424
DivisionW -116.84925 40.36695 -2.895 0.004141 **
PutOuts 0.28189 0.07744 3.640 0.000333 ***
Assists 0.37107 0.22120 1.678 0.094723 .
Errors -3.36076 4.39163 -0.765 0.444857
NewLeagueN -24.76233 79.00263 -0.313 0.754218
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 315.6 on 243 degrees of freedom
Multiple R-squared: 0.5461, Adjusted R-squared: 0.5106
F-statistic: 15.39 on 19 and 243 DF, p-value: < 2.2e-16Nous sommes sur un modèle comprenant des variables quantitatives et qualitative ce qui le rapproche d’une modélisation ANOVA.
Résultats
Ce qu’on peut remarquer en premier sur ce modèle c’est que beaucoup de variables ont un effet non significatif.
Aussi, ce modèle offre des valeurs de \(R^2\) et \(R^2_{adjusted}\) autour de 0.5 ce qui témoigne d’une mauvaise qualité d’ajustement du modèle.
Et enfin, l’écart type résiduel est de 315.6 ce qui est assez important et témoigne d’un modèle peu précis.
Le coefficient de détermination linéaire, noté \(R^2\), est une mesure de la qualité de la prédiction d’une régression linéaire.
Une formulation simple serait : \[R^2 = 1 - \frac{\sum_{i=1}^n(y_i - \hat{y}_i)^2}{\sum_{i=1}^n(y_i - \bar{y}_i)^2}\] où \(n\) est le nombre de mesures, \(y_i\) la valeur de la ième mesure , \(\hat{y}_i\) la valeur prédite correspondante et \(\bar{y}_i\) la moyenne des mesures.
Ainsi, si le coefficient est proche de 1, cela veut dire que notre prediction est proche de la réalité. Tandis qu’un modèle “de base” prédirait toujours une valeur de \(y_i\) proche de la moyenne \(\bar{y}_i\) ce qui nous donnerait un \(R^2\) proche de 0.
Le \(R^2_{adjusted}\) permet quant à lui de rendre compte du phénomène d’augmentation automatique du \(R^2\) lorsque des variables explicatives supplémentaires sont ajoutées au modèle. Il est donc très utile à regarder dans les cas de grande dimension.
Pour tenter de trouver un meilleur ajustment, il est important d’analyser d’avantage le lien entre toutes les variables explicatives. On utilise alors communément le VIF (variance inflation factor).
On obtient alors pour chacune de nos variable une valeur qui, plus elle est élevée, témoigne de la multicolinéarité entre nos variables explicatives.
vif(mod1) AtBat Hits HmRun Runs RBI Walks Years
22.944366 30.281255 7.758668 15.246418 11.921715 4.148712 9.313280
CAtBat CHits CHmRun CRuns CRBI CWalks League
251.561160 502.954289 46.488462 162.520810 131.965858 19.744105 4.134115
Division PutOuts Assists Errors NewLeague
1.075398 1.236317 2.709341 2.214543 4.099063 my_VIFplot(vif(mod1))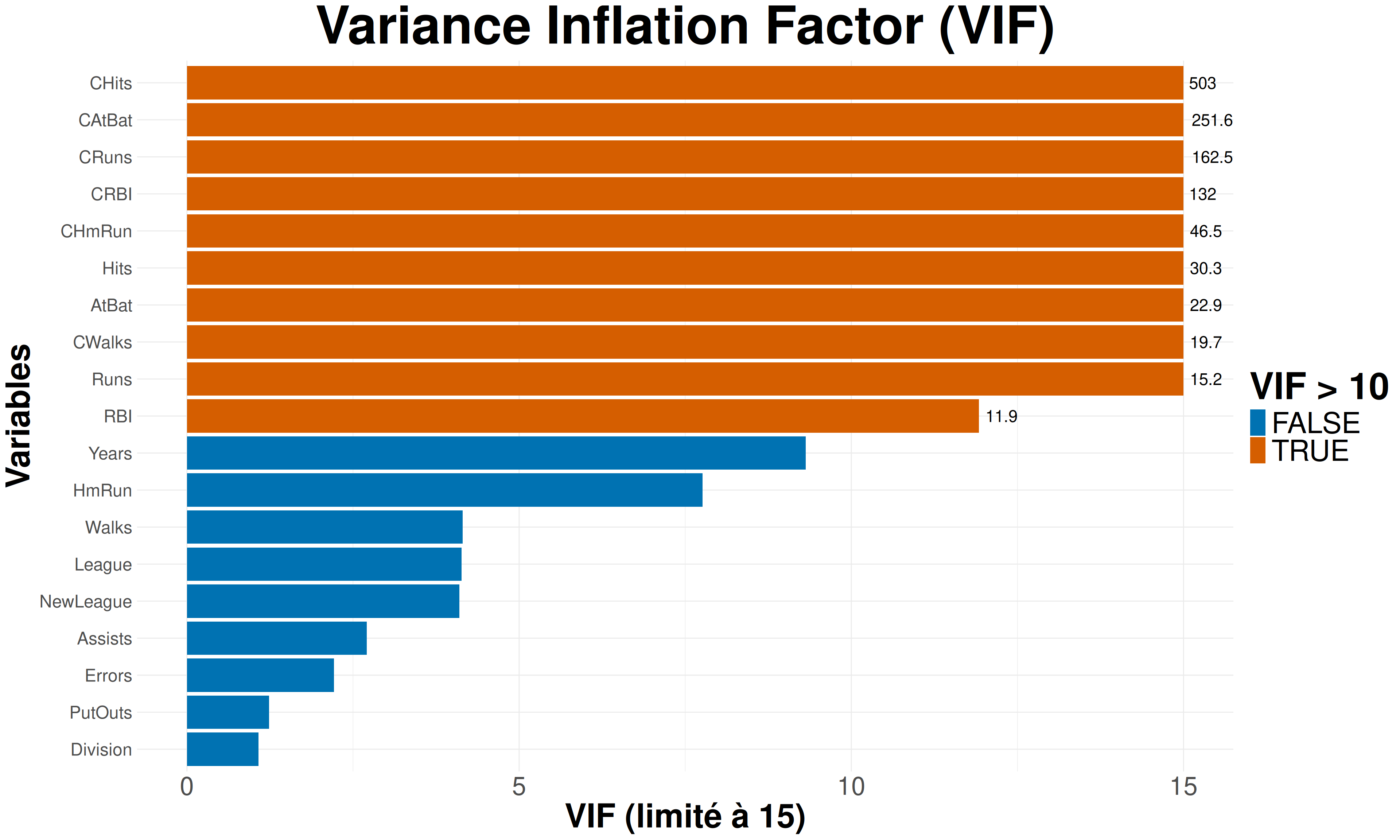
On remarque ainsi que beaucoup de valeurs sont supérieurs à 10 ce qui s’interprète communément comme la précence d’une forte colinéarité sur nos variables explicatives.
Cette colinéarité se constatait déjà durant les analyses descriptives via les graphes de corrélations (d’où l’importance de ne pas se lancer trop rapidement dans les analyses inférentielles).
Maintenant, on va donc tenter de trouver le meilleur sous-modèle possible. Pour cela on va suivre la procédure suivante :
mettre en oeuvre une méthode de sélection automatique exhaustive et observer l’évolution des SCR (Sommes de Carrés Résiduels) pour les modèles retenus en fonction de leur taille.
déduire de ces SCR le \(R^2\), \(R^2_{adjusted}\), AIC, BIC et \(C_p\) correspondants. Les comparer avec les valeurs fournies dans le summary de regsubsets et tracer leur évolution en fonction de la taille du modèle.
Puis reproduire la même procédure avec des séléctions backward, forward et stepwise
Tout d’abord, on va définir un nouveau modèle simple ne comprenant que l’intercept.
mod0 <- lm(Salary~1,
Hitters_Without_NA)
summary(mod0)$calllm(formula = Salary ~ 1, data = Hitters_Without_NA)Le principe de ces méthodes de régression avec sélection de variables est de tester et comparer les différents modèles possibles avec nos variables en allant du modèle le plus simple \(y \sim 1\) jusqu’au modèle le plus complet \(y \sim .\) ou l’inverse. Puis à chaque étape de rajout ou de suppression d’une variable dans le modèles, on sélectionne le meilleur modèle via le critère de notre choix.
Un rappel sur nos critère se trouve dans la partie Setup, onglet Fonction, de ce document avec la création de fonction pour les calculer.
selec_auto <- regsubsets(Salary~.,
Hitters_Without_NA,
method = "exhaustive",
nvmax = 19 # maximum size of subsets to examine
)
# selec_auto %>% summary()On va déjà commencer par regarder la valeur du critère en fonction des variables des différents modèles testés.
par(mfrow=c(2,2))
plot(selec_auto, scale = 'bic')
plot(selec_auto, scale = 'Cp')
plot(selec_auto, scale = 'r2')
plot(selec_auto, scale = 'adjr2') 
Résultats
Ici on remarque clairement que toutes nos variables ne sont pas gardés lorsque l’on cherche à optimiser nos critères.
Aussi, on peut voir encore de faibles valeurs pour les \(R^2\) et \(R^2_{adjusted}\) pouvant témoigner d’un mauvais ajustement de modèle.
plot.regsubsets de {leaps} ne prend pas directement “aic” comme option de scale. Pour une sélection basée sur AIC, une approche alternative consiste à utiliser la fonction stepAIC du package {MASS}, qui permet une sélection pas à pas basée sur AIC.
Regardons un peut l’évolution de la Somme des Carrés Résiduels (SCR).
SCR <- summary(selec_auto)$rss
Criteria_plot(SCR, crit_name = "Somme des Carrés Résiduels")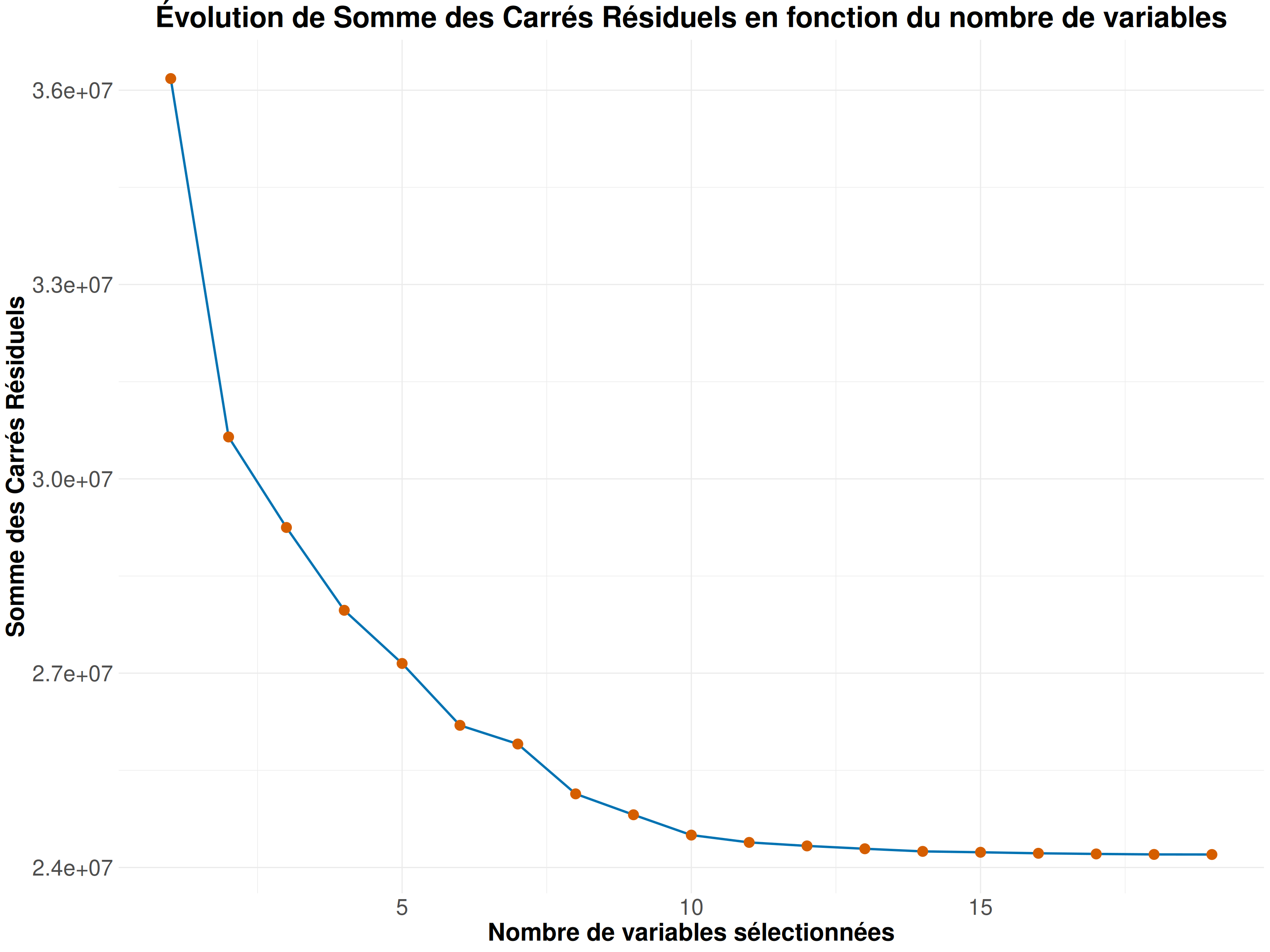
Maintenant regardons les autres critères mentionnés précédemment.
r2 <- r2_fun(Hitters_Without_NA$Salary, SCR)
r2a <- r2a_fun(Hitters_Without_NA$Salary, SCR)
cp <- cp_fun(mod1, SCR)
aic <- aic_fun(SCR)
bic <- bic_fun(SCR)
grid.arrange(Criteria_plot(r2, crit_name = "R2"),
Criteria_plot(r2a, crit_name = "R2 ajusté"),
Criteria_plot(cp, crit_name = "Cp"),
Criteria_plot(aic, crit_name = "AIC"),
Criteria_plot(bic, crit_name = "BIC"),
ncol = 3)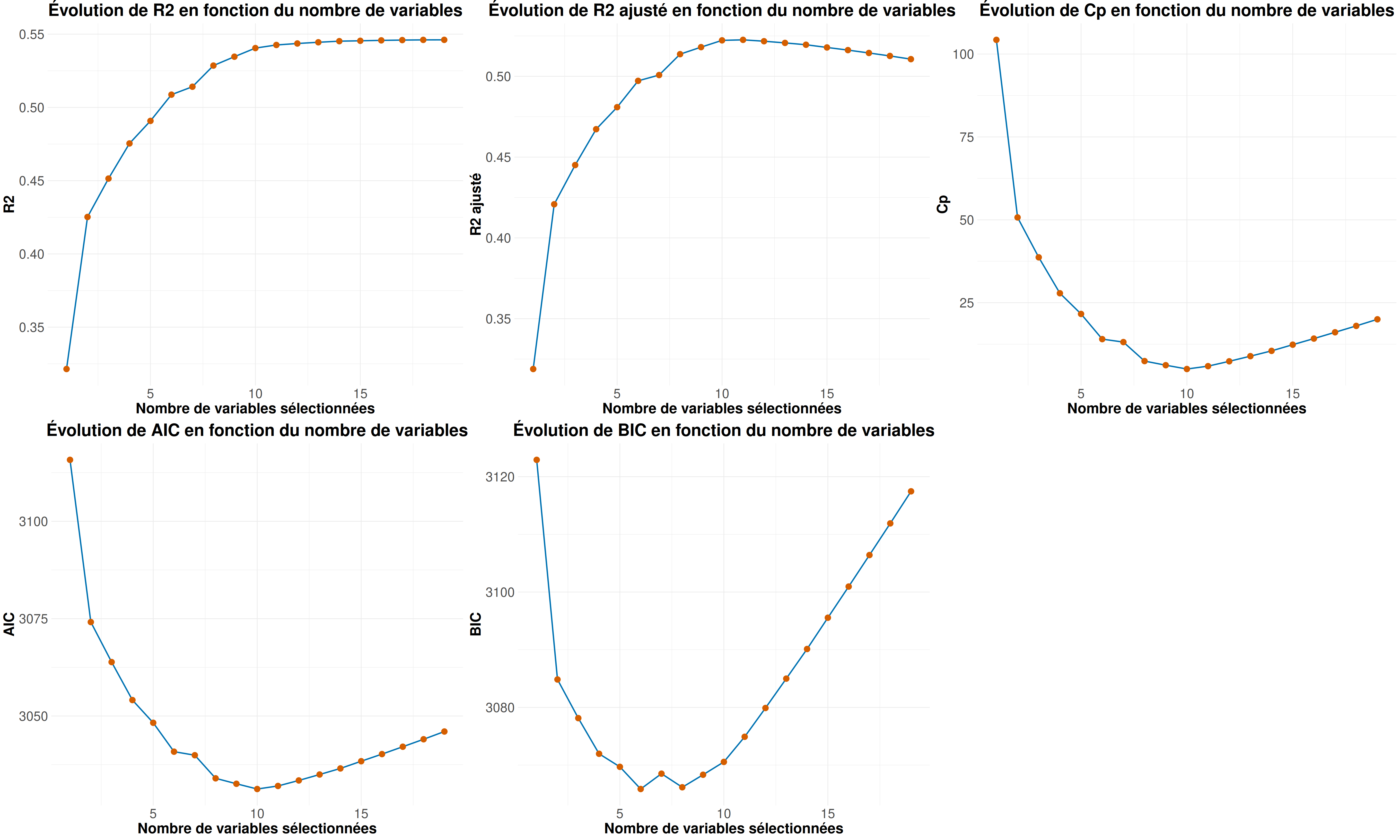
On peut ainsi voir que ce sont plutôt des modèles entre 5 et 10 variables qui optimisent nos critères (donc pas un modèle avec toutes nos variables).
Résultats
Regardons donc pour chaque critère quel est le modèle qui ressort comme le meilleur
criteria_df <- data.frame(r2, r2a, cp, aic, bic)
Best_model(selec_auto, criteria_df)Meilleur modèle selon r2 = 0.546 : Modèle avec 19 variables
(Intercept) AtBat Hits HmRun Runs RBI Walks Years CAtBat CHits CHmRun CRuns CRBI CWalks LeagueN DivisionW PutOuts Assists Errors NewLeagueN
Meilleur modèle selon r2a = 0.523 : Modèle avec 11 variables
(Intercept) AtBat Hits Walks CAtBat CRuns CRBI CWalks LeagueN DivisionW PutOuts Assists
Meilleur modèle selon cp = 5.009 : Modèle avec 10 variables
(Intercept) AtBat Hits Walks CAtBat CRuns CRBI CWalks DivisionW PutOuts Assists
Meilleur modèle selon aic = 3031.258 : Modèle avec 10 variables
(Intercept) AtBat Hits Walks CAtBat CRuns CRBI CWalks DivisionW PutOuts Assists
Meilleur modèle selon bic = 3065.851 : Modèle avec 6 variables
(Intercept) AtBat Hits Walks CRBI DivisionW PutOuts
Cette fois ci on va regarder en sélection backward. D’abord, on fait à nouveau avec la fonction regsubset.
selec_back <- regsubsets(Salary~.,
Hitters_Without_NA,
method = "backward",
nvmax = 19)par(mfrow=c(2,2))
plot(selec_back, scale = 'bic')
plot(selec_back, scale = 'Cp')
plot(selec_back, scale = 'r2')
plot(selec_back, scale = 'adjr2') 
Résultats
On remarque à nouveau une importante sélection de variables.
Mais ici aussi on a encore de faibles valeurs pour les \(R^2\) et \(R^2_{adjusted}\) pouvant témoigner d’un mauvais ajustement de modèle.
SCR <- summary(selec_back)$rss
r2 <- r2_fun(Hitters_Without_NA$Salary, SCR)
r2a <- r2a_fun(Hitters_Without_NA$Salary, SCR)
cp <- cp_fun(mod1, SCR)
aic <- aic_fun(SCR)
bic <- bic_fun(SCR)
grid.arrange(Criteria_plot(r2, crit_name = "R2"),
Criteria_plot(r2a, crit_name = "R2 ajusté"),
Criteria_plot(cp, crit_name = "Cp"),
Criteria_plot(SCR, crit_name = "Somme des Carrés Résiduels"),
Criteria_plot(aic, crit_name = "AIC"),
Criteria_plot(bic, crit_name = "BIC"),
ncol = 3)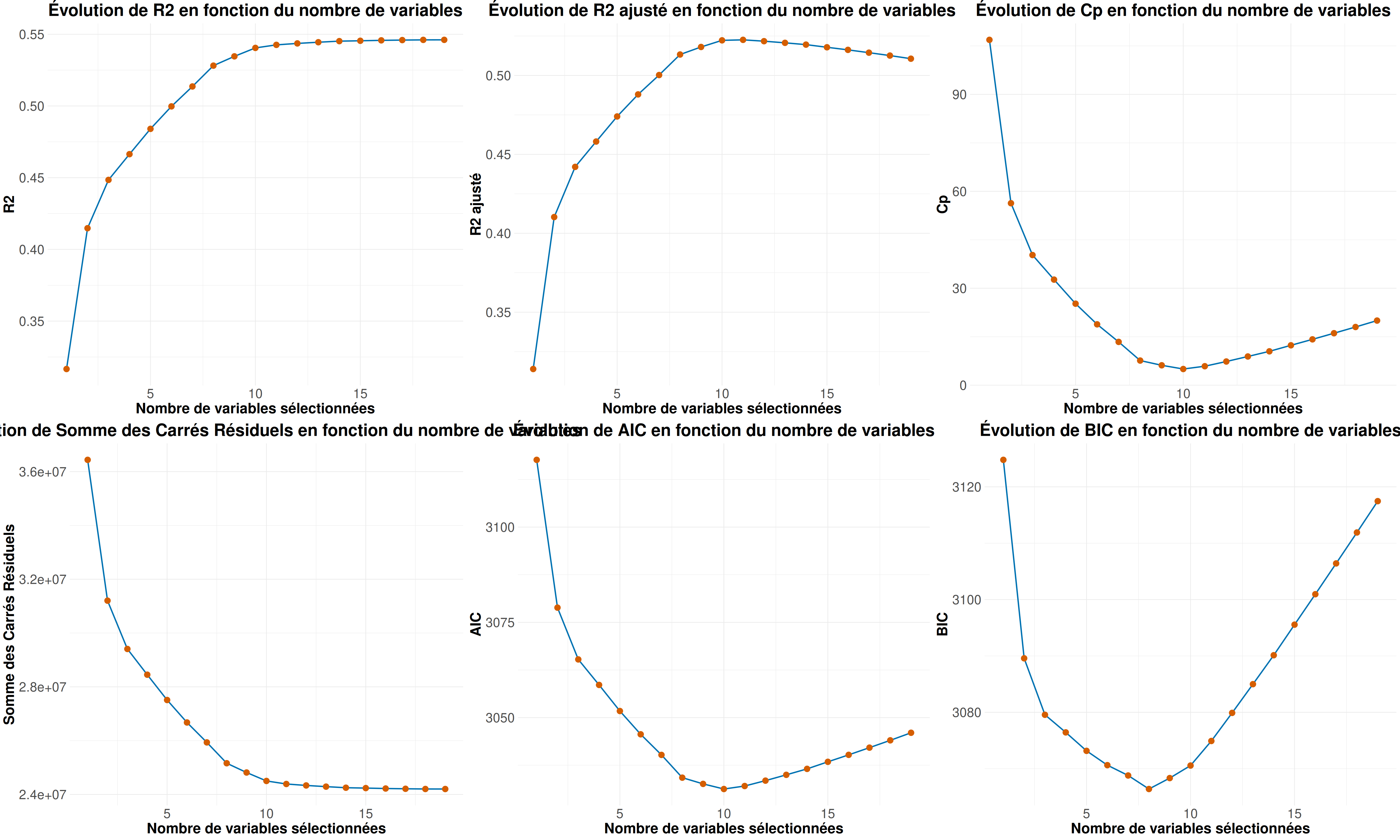
Résultats
Regardons donc pour chaque critère quel est le modèle qui ressort comme le meilleur
criteria_df <- data.frame(r2, r2a, cp, aic, bic)
Best_model(selec_back, criteria_df)Meilleur modèle selon r2 = 0.546 : Modèle avec 19 variables
(Intercept) AtBat Hits HmRun Runs RBI Walks Years CAtBat CHits CHmRun CRuns CRBI CWalks LeagueN DivisionW PutOuts Assists Errors NewLeagueN
Meilleur modèle selon r2a = 0.523 : Modèle avec 11 variables
(Intercept) AtBat Hits Walks CAtBat CRuns CRBI CWalks LeagueN DivisionW PutOuts Assists
Meilleur modèle selon cp = 5.009 : Modèle avec 10 variables
(Intercept) AtBat Hits Walks CAtBat CRuns CRBI CWalks DivisionW PutOuts Assists
Meilleur modèle selon aic = 3031.258 : Modèle avec 10 variables
(Intercept) AtBat Hits Walks CAtBat CRuns CRBI CWalks DivisionW PutOuts Assists
Meilleur modèle selon bic = 3066.386 : Modèle avec 8 variables
(Intercept) AtBat Hits Walks CRuns CRBI CWalks DivisionW PutOuts
On peut également utiliser la fonction step de la library {stats}. Pour cela, on part du plus gros modèle défini précédemment par mod1.
La fonction step nous propose quel critère nous voulons utiliser pour la sélection entre le BIC, AIC et \(C_p\).
n <- nrow(Hitters_Without_NA)
modselect_back_bic <- step(mod1,
scope = formula(mod1),
trace = FALSE, # trace = TRUE permet de voir le détail des étapes
direction = c("backward"),
k = log(n) # BIC selection
)Puis on peut regarder le modèle qui optimise le critère utilisé pour la selection.
modselect_back_bic %>% summary()
Call:
lm(formula = Salary ~ AtBat + Hits + Walks + CRuns + CRBI + CWalks +
Division + PutOuts, data = Hitters_Without_NA)
Residuals:
Min 1Q Median 3Q Max
-794.06 -171.94 -28.48 133.36 2017.83
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 117.15204 65.07016 1.800 0.072985 .
AtBat -2.03392 0.52282 -3.890 0.000128 ***
Hits 6.85491 1.65215 4.149 4.56e-05 ***
Walks 6.44066 1.52212 4.231 3.25e-05 ***
CRuns 0.70454 0.24869 2.833 0.004981 **
CRBI 0.52732 0.18861 2.796 0.005572 **
CWalks -0.80661 0.26395 -3.056 0.002483 **
DivisionW -123.77984 39.28749 -3.151 0.001824 **
PutOuts 0.27539 0.07431 3.706 0.000259 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 314.7 on 254 degrees of freedom
Multiple R-squared: 0.5281, Adjusted R-squared: 0.5133
F-statistic: 35.54 on 8 and 254 DF, p-value: < 2.2e-16La fonction step propose aussi une selection avec AIC et Cp.
modselect_back_aic <- step(mod1,
scope = formula(mod1),
trace = FALSE,
direction = c("backward"),
k = 2 # AIC selection
)
modselect_back_aic %>% summary()
Call:
lm(formula = Salary ~ AtBat + Hits + Walks + CAtBat + CRuns +
CRBI + CWalks + Division + PutOuts + Assists, data = Hitters_Without_NA)
Residuals:
Min 1Q Median 3Q Max
-939.11 -176.87 -34.08 130.90 1910.55
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 162.53544 66.90784 2.429 0.015830 *
AtBat -2.16865 0.53630 -4.044 7.00e-05 ***
Hits 6.91802 1.64665 4.201 3.69e-05 ***
Walks 5.77322 1.58483 3.643 0.000327 ***
CAtBat -0.13008 0.05550 -2.344 0.019858 *
CRuns 1.40825 0.39040 3.607 0.000373 ***
CRBI 0.77431 0.20961 3.694 0.000271 ***
CWalks -0.83083 0.26359 -3.152 0.001818 **
DivisionW -112.38006 39.21438 -2.866 0.004511 **
PutOuts 0.29737 0.07444 3.995 8.50e-05 ***
Assists 0.28317 0.15766 1.796 0.073673 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 311.8 on 252 degrees of freedom
Multiple R-squared: 0.5405, Adjusted R-squared: 0.5223
F-statistic: 29.64 on 10 and 252 DF, p-value: < 2.2e-16modselect_back_cp <- step(mod1,
scope = formula(mod1),
trace = FALSE,
direction = c("backward"),
k = 1 # Cp selection
)
modselect_back_cp %>% summary()
Call:
lm(formula = Salary ~ AtBat + Hits + Walks + CAtBat + CRuns +
CRBI + CWalks + League + Division + PutOuts + Assists, data = Hitters_Without_NA)
Residuals:
Min 1Q Median 3Q Max
-932.2 -175.4 -29.2 130.4 1897.2
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 135.75122 71.34623 1.903 0.058223 .
AtBat -2.12775 0.53746 -3.959 9.81e-05 ***
Hits 6.92370 1.64612 4.206 3.62e-05 ***
Walks 5.62028 1.59064 3.533 0.000488 ***
CAtBat -0.13899 0.05609 -2.478 0.013870 *
CRuns 1.45533 0.39270 3.706 0.000259 ***
CRBI 0.78525 0.20978 3.743 0.000225 ***
CWalks -0.82286 0.26361 -3.121 0.002010 **
LeagueN 43.11162 39.96612 1.079 0.281755
DivisionW -111.14603 39.21835 -2.834 0.004970 **
PutOuts 0.28941 0.07478 3.870 0.000139 ***
Assists 0.26883 0.15816 1.700 0.090430 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 311.7 on 251 degrees of freedom
Multiple R-squared: 0.5426, Adjusted R-squared: 0.5226
F-statistic: 27.07 on 11 and 251 DF, p-value: < 2.2e-16Résultats
Avec la fonction step nous avons le modèle utilisant le critère BIC qui nous permet d’avoir toutes nos variables significatives (sauf l’intercept ce qui pourrait nous donner envie de faire des modèles sans).
Par contre, nos valeurs de \(R^2\) et \(R^2_{adjusted}\) sont encore assez faible pour considérer ces modèles comme étant de très bonne qualité.
Aussi, si on veut comparer le modèle initial et le modèle final, on peut utiliser la fonction anova. Cela permet de voir si la sélection de variables a significativement amélioré l’ajustement.
anova(mod0, modselect_back_bic, test = "Chisq")Analysis of Variance Table
Model 1: Salary ~ 1
Model 2: Salary ~ AtBat + Hits + Walks + CRuns + CRBI + CWalks + Division +
PutOuts
Res.Df RSS Df Sum of Sq Pr(>Chi)
1 262 53319113
2 254 25159234 8 28159879 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1De manière logique on voit donc tout de même que le modèle avec nos variable explicatives sélectionnées (ici celui avec selection via le critère BIC) propose un meilleur ajustement que celui sans variable.
Cette fois ci on va regarder en sélection forward. D’abord, on fait à nouveau avec la fonction regsubset.
selec_forw <- regsubsets(Salary~.,
Hitters_Without_NA,
method = "forward",
nvmax = 19)par(mfrow=c(2,2))
plot(selec_forw, scale = 'bic')
plot(selec_forw, scale = 'Cp')
plot(selec_forw, scale = 'r2')
plot(selec_forw, scale = 'adjr2') 
Résultats
On remarque à nouveau une importante sélection de variables.
Mais ici aussi on a encore de faibles valeurs pour les \(R^2\) et \(R^2_{adjusted}\) pouvant témoigner d’un mauvais ajustement de modèle.
SCR <- summary(selec_forw)$rss
r2 <- r2_fun(Hitters_Without_NA$Salary, SCR)
r2a <- r2a_fun(Hitters_Without_NA$Salary, SCR)
cp <- cp_fun(mod1, SCR)
aic <- aic_fun(SCR)
bic <- bic_fun(SCR)
grid.arrange(Criteria_plot(r2, crit_name = "R2"),
Criteria_plot(r2a, crit_name = "R2 ajusté"),
Criteria_plot(cp, crit_name = "Cp"),
Criteria_plot(SCR, crit_name = "Somme des Carrés Résiduels"),
Criteria_plot(aic, crit_name = "AIC"),
Criteria_plot(bic, crit_name = "BIC"),
ncol = 3)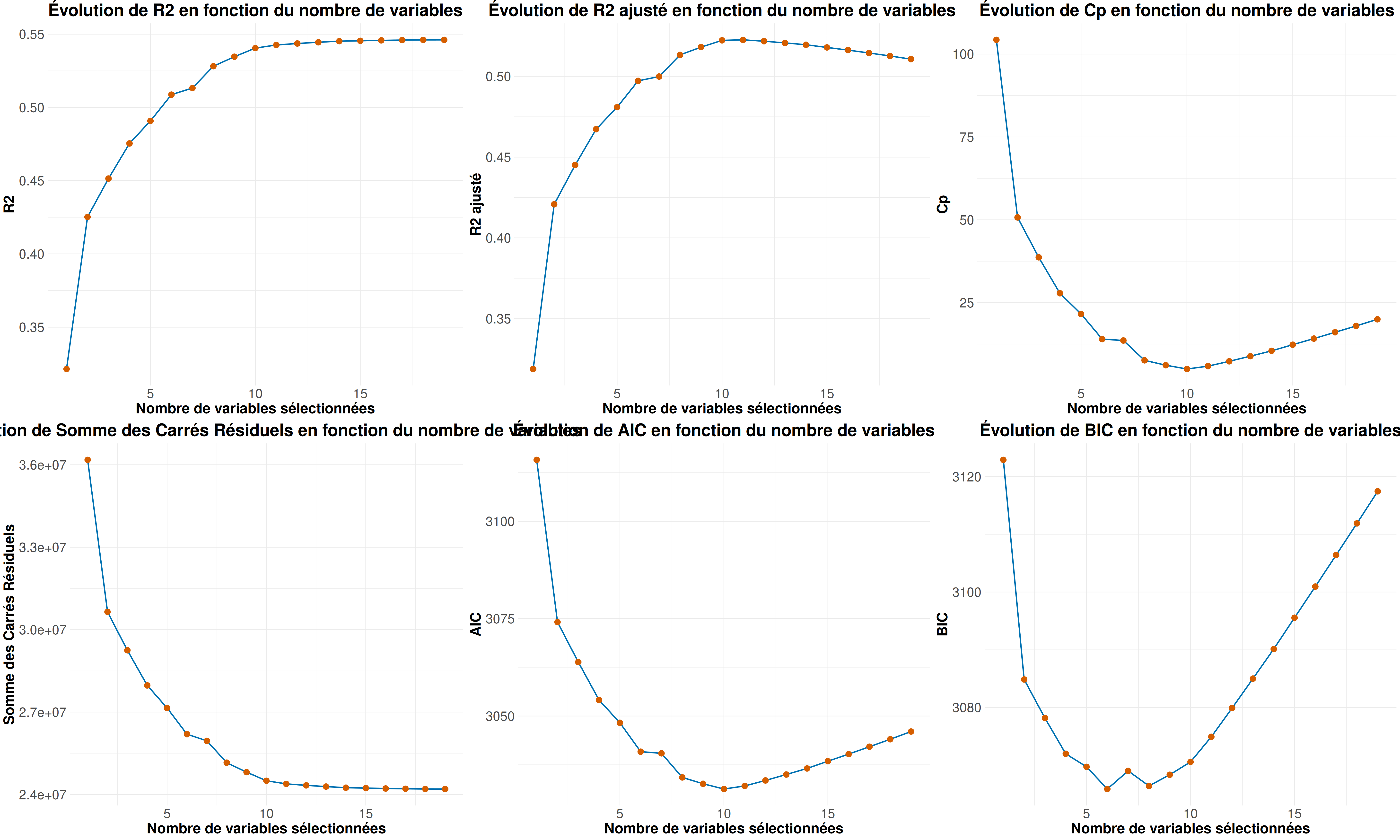
Résultats
Regardons donc pour chaque critère quel est le modèle qui ressort comme le meilleur
criteria_df <- data.frame(r2, r2a, cp, aic, bic)
Best_model(selec_forw, criteria_df)Meilleur modèle selon r2 = 0.546 : Modèle avec 19 variables
(Intercept) AtBat Hits HmRun Runs RBI Walks Years CAtBat CHits CHmRun CRuns CRBI CWalks LeagueN DivisionW PutOuts Assists Errors NewLeagueN
Meilleur modèle selon r2a = 0.523 : Modèle avec 11 variables
(Intercept) AtBat Hits Walks CAtBat CRuns CRBI CWalks LeagueN DivisionW PutOuts Assists
Meilleur modèle selon cp = 5.009 : Modèle avec 10 variables
(Intercept) AtBat Hits Walks CAtBat CRuns CRBI CWalks DivisionW PutOuts Assists
Meilleur modèle selon aic = 3031.258 : Modèle avec 10 variables
(Intercept) AtBat Hits Walks CAtBat CRuns CRBI CWalks DivisionW PutOuts Assists
Meilleur modèle selon bic = 3065.851 : Modèle avec 6 variables
(Intercept) AtBat Hits Walks CRBI DivisionW PutOuts
On peut également utiliser la fonction step de la library {stats}. Cette fois ci il faut définir en modèle de départ le plus petit modèle (celui composé seulement de l’intercept).
La fonction step nous propose quel critère nous voulons utiliser pour la sélection entre le BIC, AIC et \(C_p\).
modselect_forw_bic <- step(mod0,
scope = formula(mod1),
trace = FALSE, # trace = TRUE permet de voir le détail des étapes
direction = c("forward"),
k = log(n) # BIC selection
)Puis on peut regarder le modèle qui optimise le critère utilisé pour la selection.
modselect_forw_bic %>% summary()
Call:
lm(formula = Salary ~ CRBI + Hits + PutOuts + Division + AtBat +
Walks, data = Hitters_Without_NA)
Residuals:
Min 1Q Median 3Q Max
-873.11 -181.72 -25.91 141.77 2040.47
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 91.51180 65.00006 1.408 0.160382
CRBI 0.64302 0.06443 9.979 < 2e-16 ***
Hits 7.60440 1.66254 4.574 7.46e-06 ***
PutOuts 0.26431 0.07477 3.535 0.000484 ***
DivisionW -122.95153 39.82029 -3.088 0.002239 **
AtBat -1.86859 0.52742 -3.543 0.000470 ***
Walks 3.69765 1.21036 3.055 0.002488 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 319.9 on 256 degrees of freedom
Multiple R-squared: 0.5087, Adjusted R-squared: 0.4972
F-statistic: 44.18 on 6 and 256 DF, p-value: < 2.2e-16La fonction step propose aussi une selection avec AIC et Cp.
modselect_forw_aic <- step(mod0,
scope = formula(mod1),
trace = FALSE,
direction = c("forward"),
k = 2 # AIC selection
)
modselect_forw_aic %>% summary()
Call:
lm(formula = Salary ~ CRBI + Hits + PutOuts + Division + AtBat +
Walks + CWalks + CRuns + CAtBat + Assists, data = Hitters_Without_NA)
Residuals:
Min 1Q Median 3Q Max
-939.11 -176.87 -34.08 130.90 1910.55
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 162.53544 66.90784 2.429 0.015830 *
CRBI 0.77431 0.20961 3.694 0.000271 ***
Hits 6.91802 1.64665 4.201 3.69e-05 ***
PutOuts 0.29737 0.07444 3.995 8.50e-05 ***
DivisionW -112.38006 39.21438 -2.866 0.004511 **
AtBat -2.16865 0.53630 -4.044 7.00e-05 ***
Walks 5.77322 1.58483 3.643 0.000327 ***
CWalks -0.83083 0.26359 -3.152 0.001818 **
CRuns 1.40825 0.39040 3.607 0.000373 ***
CAtBat -0.13008 0.05550 -2.344 0.019858 *
Assists 0.28317 0.15766 1.796 0.073673 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 311.8 on 252 degrees of freedom
Multiple R-squared: 0.5405, Adjusted R-squared: 0.5223
F-statistic: 29.64 on 10 and 252 DF, p-value: < 2.2e-16modselect_forw_cp <- step(mod0,
scope = formula(mod1),
trace = FALSE,
direction = c("forward"),
k = 1 # Cp selection
)
modselect_forw_cp %>% summary()
Call:
lm(formula = Salary ~ CRBI + Hits + PutOuts + Division + AtBat +
Walks + CWalks + CRuns + CAtBat + Assists + League, data = Hitters_Without_NA)
Residuals:
Min 1Q Median 3Q Max
-932.2 -175.4 -29.2 130.4 1897.2
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 135.75122 71.34623 1.903 0.058223 .
CRBI 0.78525 0.20978 3.743 0.000225 ***
Hits 6.92370 1.64612 4.206 3.62e-05 ***
PutOuts 0.28941 0.07478 3.870 0.000139 ***
DivisionW -111.14603 39.21835 -2.834 0.004970 **
AtBat -2.12775 0.53746 -3.959 9.81e-05 ***
Walks 5.62028 1.59064 3.533 0.000488 ***
CWalks -0.82286 0.26361 -3.121 0.002010 **
CRuns 1.45533 0.39270 3.706 0.000259 ***
CAtBat -0.13899 0.05609 -2.478 0.013870 *
Assists 0.26883 0.15816 1.700 0.090430 .
LeagueN 43.11162 39.96612 1.079 0.281755
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 311.7 on 251 degrees of freedom
Multiple R-squared: 0.5426, Adjusted R-squared: 0.5226
F-statistic: 27.07 on 11 and 251 DF, p-value: < 2.2e-16Résultats
Avec la fonction step nous avons le modèle utilisant le critère BIC qui nous permet d’avoir toutes nos variables significatives (sauf l’intercept ce qui pourrait nous donner envie de faire des modèles sans).
Par contre, nos valeurs de \(R^2\) et \(R^2_{adjusted}\) sont encore assez faible pour considérer ces modèles comme étant de très bonne qualité.
Aussi, si on veut comparer le modèle initial et le modèle final, on peut utiliser la fonction anova. Cela permet de voir si la sélection de variables a significativement amélioré l’ajustement.
anova(mod0, modselect_forw_bic, test = "Chisq")Analysis of Variance Table
Model 1: Salary ~ 1
Model 2: Salary ~ CRBI + Hits + PutOuts + Division + AtBat + Walks
Res.Df RSS Df Sum of Sq Pr(>Chi)
1 262 53319113
2 256 26194904 6 27124209 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1De manière logique on voit donc tout de même que le modèle avec nos variable explicatives sélectionnées (ici celui avec selection via le critère BIC) propose un meilleur ajustement que celui sans variable.
Maintenant on va regarder en sélection both. D’abord, on fait à nouveau avec la fonction regsubset.
selec_seq <- regsubsets(Salary~.,
Hitters_Without_NA,
method = "seqrep",
nvmax = 19)par(mfrow=c(2,2))
plot(selec_seq, scale = 'bic')
plot(selec_seq, scale = 'Cp')
plot(selec_seq, scale = 'r2')
plot(selec_seq, scale = 'adjr2') 
Résultats
On remarque à nouveau une importante sélection de variables.
Mais ici aussi on a encore de faibles valeurs pour les \(R^2\) et \(R^2_{adjusted}\) pouvant témoigner d’un mauvais ajustement de modèle.
SCR <- summary(selec_seq)$rss
r2 <- r2_fun(Hitters_Without_NA$Salary, SCR)
r2a <- r2a_fun(Hitters_Without_NA$Salary, SCR)
cp <- cp_fun(mod1, SCR)
aic <- aic_fun(SCR)
bic <- bic_fun(SCR)
grid.arrange(Criteria_plot(r2, crit_name = "R2"),
Criteria_plot(r2a, crit_name = "R2 ajusté"),
Criteria_plot(cp, crit_name = "Cp"),
Criteria_plot(SCR, crit_name = "Somme des Carrés Résiduels"),
Criteria_plot(aic, crit_name = "AIC"),
Criteria_plot(bic, crit_name = "BIC"),
ncol = 3)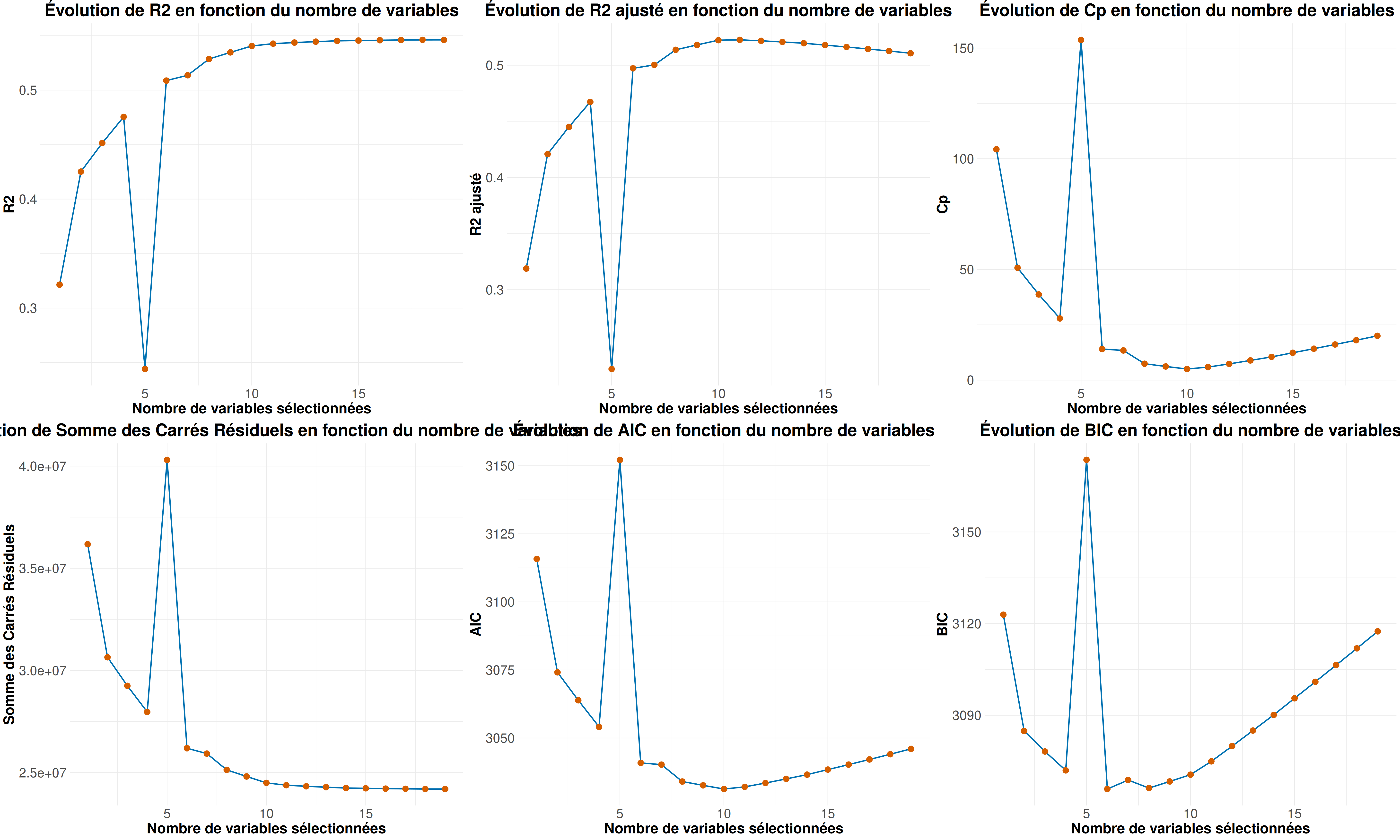
Résultats
Regardons donc pour chaque critère quel est le modèle qui ressort comme le meilleur
criteria_df <- data.frame(r2, r2a, cp, aic, bic)
Best_model(selec_seq, criteria_df)Meilleur modèle selon r2 = 0.546 : Modèle avec 19 variables
(Intercept) AtBat Hits HmRun Runs RBI Walks Years CAtBat CHits CHmRun CRuns CRBI CWalks LeagueN DivisionW PutOuts Assists Errors NewLeagueN
Meilleur modèle selon r2a = 0.523 : Modèle avec 11 variables
(Intercept) AtBat Hits Walks CAtBat CRuns CRBI CWalks LeagueN DivisionW PutOuts Assists
Meilleur modèle selon cp = 5.009 : Modèle avec 10 variables
(Intercept) AtBat Hits Walks CAtBat CRuns CRBI CWalks DivisionW PutOuts Assists
Meilleur modèle selon aic = 3031.258 : Modèle avec 10 variables
(Intercept) AtBat Hits Walks CAtBat CRuns CRBI CWalks DivisionW PutOuts Assists
Meilleur modèle selon bic = 3065.851 : Modèle avec 6 variables
(Intercept) AtBat Hits Walks CRBI DivisionW PutOuts
On peut également utiliser la fonction step de la library {stats}.
La fonction step nous propose quel critère nous voulons utiliser pour la sélection entre le BIC, AIC et \(C_p\).
modselect_seq_bic <- step(mod0,
scope = formula(mod1),
trace = FALSE,
direction = c("both"),
k = log(n))
modselect_seq_bic %>% summary()
Call:
lm(formula = Salary ~ CRBI + Hits + PutOuts + Division + AtBat +
Walks, data = Hitters_Without_NA)
Residuals:
Min 1Q Median 3Q Max
-873.11 -181.72 -25.91 141.77 2040.47
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 91.51180 65.00006 1.408 0.160382
CRBI 0.64302 0.06443 9.979 < 2e-16 ***
Hits 7.60440 1.66254 4.574 7.46e-06 ***
PutOuts 0.26431 0.07477 3.535 0.000484 ***
DivisionW -122.95153 39.82029 -3.088 0.002239 **
AtBat -1.86859 0.52742 -3.543 0.000470 ***
Walks 3.69765 1.21036 3.055 0.002488 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 319.9 on 256 degrees of freedom
Multiple R-squared: 0.5087, Adjusted R-squared: 0.4972
F-statistic: 44.18 on 6 and 256 DF, p-value: < 2.2e-16modselect_seq_aic <- step(mod0,
scope = formula(mod1),
trace = FALSE,
direction = c("both"),
k = 2)
modselect_seq_aic %>% summary()
Call:
lm(formula = Salary ~ CRBI + Hits + PutOuts + Division + AtBat +
Walks + CWalks + CRuns + CAtBat + Assists, data = Hitters_Without_NA)
Residuals:
Min 1Q Median 3Q Max
-939.11 -176.87 -34.08 130.90 1910.55
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 162.53544 66.90784 2.429 0.015830 *
CRBI 0.77431 0.20961 3.694 0.000271 ***
Hits 6.91802 1.64665 4.201 3.69e-05 ***
PutOuts 0.29737 0.07444 3.995 8.50e-05 ***
DivisionW -112.38006 39.21438 -2.866 0.004511 **
AtBat -2.16865 0.53630 -4.044 7.00e-05 ***
Walks 5.77322 1.58483 3.643 0.000327 ***
CWalks -0.83083 0.26359 -3.152 0.001818 **
CRuns 1.40825 0.39040 3.607 0.000373 ***
CAtBat -0.13008 0.05550 -2.344 0.019858 *
Assists 0.28317 0.15766 1.796 0.073673 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 311.8 on 252 degrees of freedom
Multiple R-squared: 0.5405, Adjusted R-squared: 0.5223
F-statistic: 29.64 on 10 and 252 DF, p-value: < 2.2e-16modselect_seq_cp <- step(mod0,
scope = formula(mod1),
trace = FALSE,
direction = c("both"),
k = 1)
modselect_seq_cp %>% summary()
Call:
lm(formula = Salary ~ CRBI + Hits + PutOuts + Division + AtBat +
Walks + CWalks + CRuns + CAtBat + Assists + League, data = Hitters_Without_NA)
Residuals:
Min 1Q Median 3Q Max
-932.2 -175.4 -29.2 130.4 1897.2
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 135.75122 71.34623 1.903 0.058223 .
CRBI 0.78525 0.20978 3.743 0.000225 ***
Hits 6.92370 1.64612 4.206 3.62e-05 ***
PutOuts 0.28941 0.07478 3.870 0.000139 ***
DivisionW -111.14603 39.21835 -2.834 0.004970 **
AtBat -2.12775 0.53746 -3.959 9.81e-05 ***
Walks 5.62028 1.59064 3.533 0.000488 ***
CWalks -0.82286 0.26361 -3.121 0.002010 **
CRuns 1.45533 0.39270 3.706 0.000259 ***
CAtBat -0.13899 0.05609 -2.478 0.013870 *
Assists 0.26883 0.15816 1.700 0.090430 .
LeagueN 43.11162 39.96612 1.079 0.281755
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 311.7 on 251 degrees of freedom
Multiple R-squared: 0.5426, Adjusted R-squared: 0.5226
F-statistic: 27.07 on 11 and 251 DF, p-value: < 2.2e-16Résultats
Avec la fonction step nous avons le modèle utilisant le critère BIC qui nous permet d’avoir toutes nos variables significatives (sauf l’intercept ce qui pourrait nous donner envie de faire des modèles sans).
Par contre, nos valeurs de \(R^2\) et \(R^2_{adjusted}\) sont encore assez faible pour considérer ces modèles comme étant de très bonne qualité.
Aussi, si on veut comparer le modèle initial et le modèle final, on peut utiliser la fonction anova. Cela permet de voir si la sélection de variables a significativement amélioré l’ajustement.
anova(mod0, modselect_seq_bic, test = "Chisq")Analysis of Variance Table
Model 1: Salary ~ 1
Model 2: Salary ~ CRBI + Hits + PutOuts + Division + AtBat + Walks
Res.Df RSS Df Sum of Sq Pr(>Chi)
1 262 53319113
2 256 26194904 6 27124209 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1De manière logique on voit donc tout de même que le modèle avec nos variable explicatives sélectionnées (ici celui avec selection via le critère BIC) propose un meilleur ajustement que celui sans variable.
Avant de finir, comparons un peut les critères que nous avons calculés avec ceux que l’on peut récupérer via le summary de regsubset (pour tous sauf l’AIC qui n’est pas présent). On se contentera de faire se comparatif seulement pour le modèle stepwise.
Pour cela regardons si nous avons régulièrement la valeur 0 (ou valeur proche) lorsque l’on fait la soustraction du critère calculé et du critère donné par regsubset :
(valeur calculée - valeur récupérée) pour le \(R^2\) : 0
(valeur calculée - valeur récupérée) pour le \(R^2_{adjusted}\) : 0
(valeur calculée - valeur récupérée) pour le \(C_p\) : 0
(valeur calculée - valeur récupérée) pour le BIC : 3214
Pour le BIC, on voit une valeur très éloigné de 0. Regardons plus en détail cette différence entre la valeur calculée et la valeur récupérée via les représentations visuelles de l’évolution du critère.
grid.arrange(Criteria_plot(bic, crit_name = "BIC"),
Criteria_plot(summary(selec_seq)$bic, crit_name = "BIC regsubstet ajusté"),
ncol = 2)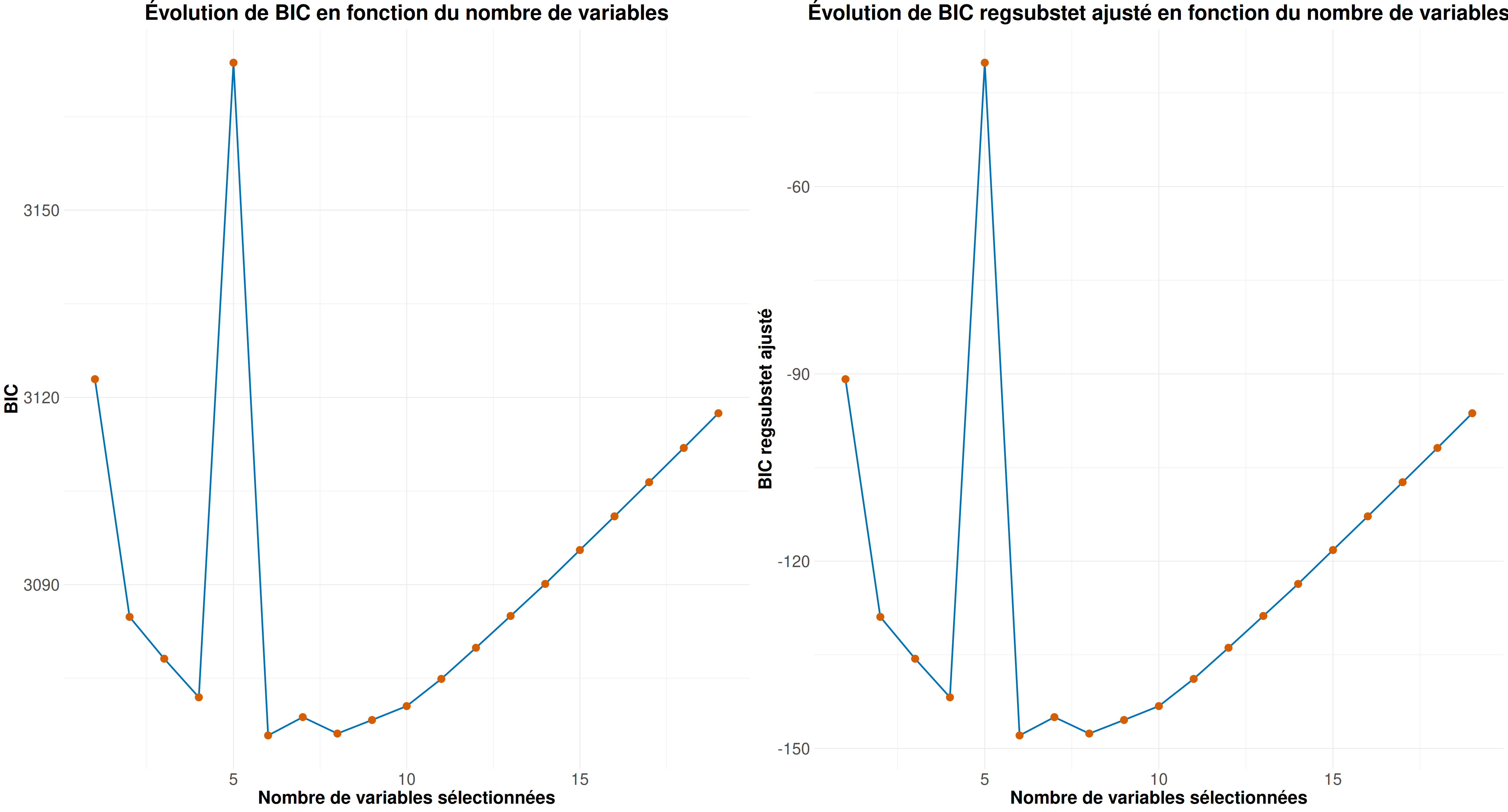
On voit que les valeurs sont différentes mais le comportement est identique. Ce qui veut dire que la différence est seulement due à une constant multiplicative près.
À la lumière des résultats de notre analyse, on peut envisager le modèle both car bien qu’il n’ait pas montré de grandes améliorations en termes de \(R^2\) et \(R^2_{adjusted}\), il a une démarche plus “souple” pour permettre de réduire le nombre de variables tout en maintenant celles qui sont significatives. Ce modèle est donc plus parcimonieux tout en conservant des variables importantes. Cependant, une réflexion supplémentaire pourrait être menée sur l’éventuelle suppression de l’intercept, ce qui nécessiterait une validation supplémentaire.
En ce qui concerne le choix final du modèle, on peut opter pour celui qui maximise le critère BIC, ce qui nous mène à un modèle avec 6 variables. Le BIC est particulièrement utile pour privilégier un modèle plus simple et plus parcimonieux, ce qui est un atout lorsqu’on cherche à éviter un surajustement. Toutefois, il est important de noter que la qualité de l’ajustement n’est pas optimale, ce qui suggère qu’il pourrait manquer certaines informations pour expliquer pleinement la variable cible (le salaire).
Enfin, la validité interne est un aspect crucial qui n’a pas été suffisamment exploré dans cette analyse. En effet, il aurait été pertinent de vérifier que toutes les hypothèses sous-jacentes des modèles étaient satisfaites. Cela aurait permis de renforcer la robustesse de nos résultats et de garantir que les conclusions qu’on sont fiables.
Donc, il serait pertinent d’examiner plus en profondeur des modèles sans intercept et la validité interne, notamment en testant les hypothèses de normalité des résidus, d’homoscédasticité (i.e variance identique des résidus), et d’indépendance des résidus.
sessioninfo::session_info(pkgs = "attached")─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.4.2 (2024-10-31)
os Ubuntu 24.04.1 LTS
system x86_64, linux-gnu
ui X11
language (EN)
collate fr_FR.UTF-8
ctype fr_FR.UTF-8
tz Europe/Paris
date 2025-03-19
pandoc 3.2 @ /usr/lib/rstudio/resources/app/bin/quarto/bin/tools/x86_64/ (via rmarkdown)
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
car * 3.1-3 2024-09-27 [1] CRAN (R 4.4.2)
carData * 3.0-5 2022-01-06 [1] CRAN (R 4.4.2)
dplyr * 1.1.4 2023-11-17 [1] CRAN (R 4.4.2)
forcats * 1.0.0 2023-01-29 [1] CRAN (R 4.4.2)
ggplot2 * 3.5.1 2024-04-23 [1] CRAN (R 4.4.2)
gridExtra * 2.3 2017-09-09 [1] CRAN (R 4.4.2)
ISLR * 1.4 2021-09-15 [1] CRAN (R 4.4.2)
kableExtra * 1.4.0 2024-01-24 [1] CRAN (R 4.4.2)
leaps * 3.2 2024-06-10 [1] CRAN (R 4.4.2)
lubridate * 1.9.4 2024-12-08 [1] CRAN (R 4.4.2)
purrr * 1.0.4 2025-02-05 [1] CRAN (R 4.4.2)
readr * 2.1.5 2024-01-10 [1] CRAN (R 4.4.2)
stringr * 1.5.1 2023-11-14 [2] CRAN (R 4.3.3)
tibble * 3.2.1 2023-03-20 [2] CRAN (R 4.3.3)
tidyr * 1.3.1 2024-01-24 [1] CRAN (R 4.4.2)
tidyverse * 2.0.0 2023-02-22 [1] CRAN (R 4.4.2)
[1] /home/clement/R/x86_64-pc-linux-gnu-library/4.4
[2] /usr/local/lib/R/site-library
[3] /usr/lib/R/site-library
[4] /usr/lib/R/library
──────────────────────────────────────────────────────────────────────────────