Show the code
# Données
library(dplyr) # manipulation des données
# Inférence
library(boot) # validation croisée
# Plots
## ggplot
library(ggplot2)# Données
library(dplyr) # manipulation des données
# Inférence
library(boot) # validation croisée
# Plots
## ggplot
library(ggplot2)my_hist <- function(data) {
cor_df <- data.frame(Correlation = data)
p <- ggplot(cor_df, aes(x = Correlation)) +
geom_histogram(fill = "skyblue",
color = "black",
bins = 20) +
labs(title = "Distribution des corrélations entre y et les variables explicatives", x = "Corrélation", y = "Fréquence") +
theme_minimal() +
theme(
plot.title = element_text(
size = 16,
face = "bold",
hjust = 0.5
),
axis.title = element_text(size = 14, face = "bold"),
axis.text = element_text(size = 12)
)
return(p)
}cost <- function(obs, pi ){
c <- mean(abs(obs - pi) > 0.5)
return(c)
} set.seed(140400)Dans ce rapport, nous allons pouvoir illustrer deux grands problèmes qui apparaissent dans le domaine de la statistique en grande dimension :
le biais de sélection
et les corrélations fortuites
Pour faire cela, nous nous baserons sur un jeu de données que l’on créera. On génère alors
\(y\) de taille \(n=100\) avec \(y_i \sim \mathcal{B}(0.5)\)
\(X\) qui contient \(p=5000\) variables explicatives qui seront toutes des réalisations indépendantes de \(n=100\) valeurs issues d’une loi \(\mathcal{N}_{(0,1)}\)
Pour cela, nous pouvons utiliser les fonction de R qui permettent de générer des variables aléatoire.
n <- 100
p <- 5000
y <- rbinom(n = 100, size = 1, prob = 0.5)
x <- matrix(rnorm(n*p, 0, 1), ncol = p) %>% as.data.frame()
Simu_data <- cbind(y, x) %>% as.data.frame()Pour la variable \(y\), il est possible de la simuler de manière deterministe y <- rep(c(0,1), n/2)
pour des raisons de repouctibilité, une graine ou seed a été défini dans le setup afin que la génération aléatoire reste identique.
Maintenant, nous pouvons déjà souligner que, théoriquement, il ne devrait pas y avoir de lien entre \(y\) et \(X\) puisque les simulations sont faites indépendament.
Pour visualiser cela, il suffit simplement de créer un vecteur qui stockera les différentes valeurs de corrélation entre \(y\) et \(x^i\) pour \(i\) allant de 1 à 5000.
cor_vect <- unlist(lapply(x, function(col) cor(col, y)))
my_hist(cor_vect)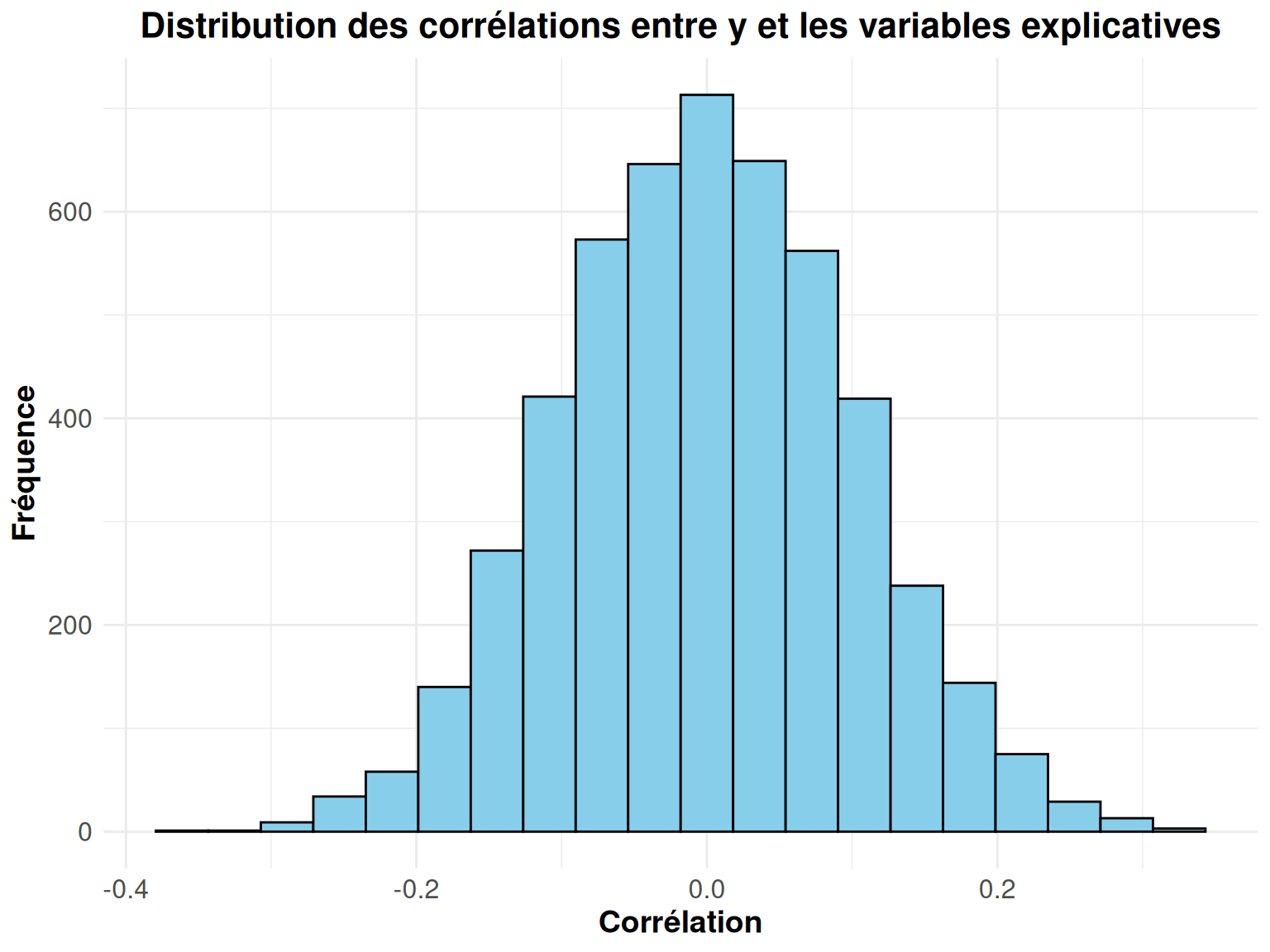
De manière général, il faut savoir qu’une méthode de prévision de \(y\) basée sur les variables explicatives s’exprime nécessairement sous la forme \(\hat{y} = f(x^1, ..., x^{5000})\). La forme de la fonction \(f\) étant généralement obtenue grâce à une estimation sur un échantillon d’apprentissage. Il faut alors découper notre jeu de données en deux échantillons, un pour l’apprentissage et un pour le test.
Dans ces méthodes, nous nous intéressons principalement au taux d’erreur de classification “test”, c’est-à-dire à la probabilité que \(\hat{y}\) soit différent de \(y\), lorsque \(y\) et \(x^1, ..., x^{5000}\) sont dans l’échantillon test et donc indépendants de l’échantillon d’apprentissage.
On peut facilement démontrer que cette probabilité est de 50% quelle que soit la méthode utilisée (cf Preuve).
Pourtant, pour illustrer nos problèmes, supposons que nous avons observé le jeu de données simulé ci-dessus, sans connaître les liens théoriques entre les variables. Nous souhaitons alors ajuster un modèle expliquant au mieux \(y\) en fonction des variables à disposition, et estimer le taux d’erreur des prévisions associées.
Nous remarquons déjà que, \(\hat{y}\) étant une combinaisons de nos variables \(x^1, ..., x^{5000}\) qui sont indépendantes de \(y\), on a \(\hat{y}\) et y sont deux variables indépendantes l’une de l’autre.
Ainsi \[\mathbb{P}(\hat{y} \neq y) = \mathbb{P}(\hat{y}=0, y=1) + \mathbb{P}(\hat{y}=1, y=0)\] \[ \quad \quad \quad \quad \quad \quad \quad \quad = \mathbb{P}(\hat{y}=0)\mathbb{P}(y=1) + \mathbb{P}(\hat{y}=1)\mathbb{P}(y=0) \quad ^{(*)}\] \[ \quad \quad \quad \quad = 0.5\mathbb{P}(\hat{y}=0) + 0.5\mathbb{P}(\hat{y}=1) \quad ^{(**)} \] \[ \quad \quad = 0.5 \left( \mathbb{P}(\hat{y}=0) + \mathbb{P}(\hat{y}=1) \right)\]
Nous reconnaissons ici une somme sur l’univers des possible de la densité discrète de \(\hat{y}\).
Celle ci est donc égale à 1 et on obtient
\[\mathbb{P}(\hat{y} \neq y) = 0.5\]
\(^{(*)} \quad \text{par indépendance de} \quad \hat{y} \quad \text{et} \quad y\)
\(^{(**)} \quad \text{car} \quad y \quad \text{suit une loi de Bernoulli de paramètre} \quad 0.5\)
Étant donné le très grand nombre de variables explicatives, on ne va garder que les 5 variables les plus corrélées avec \(y\) afin d’ajuster un modèle de régression logistique. Pour quantifier la corrélation entre la variable \(y\), qui est binaire, et une variable quantitative, deux possibilités s’offrent :
utiliser la corrélation de Pearson \(\hat{\rho}\) comme si \(y\) était une variable
utiliser le “rapport de corrélation” quantifiant le lien entre une variable qualitative et une variable quantitative : \[\hat{\eta}^2 = \frac{S^2_{inter}}{S^2_{total}}\] où \(S^2_{inter}\) est la somme des carrés “inter-classes” et \(S^2_{total}\) la somme des carrés total.
Par chance, dans notre cas nous avons que \(\hat{\eta}^2 = \hat{\rho}^2\).
Mais rassurez vous, la chance n’ayant pas forcément sa place en mathématiques, la démonstration de cette égalité pourra être trouvé dans la partie Preuve
Ainsi, la corrélation de Pearson pourra suffire pour quantifier le lien entre notre variable binaire et nos variables explicatives. Ce qui tombe bien puisqu’il s’agit de la méthode de corrélation par défaut sous \(\textit{R}\) quand on utilise la fonction \(\textit{cor}\).
Nous allons donc pouvoir garder les 5 variables les plus corrélées en valeur absolue avec \(y\) et ajuster un modèle de régression logistique faisant intervenir ces 5 variables.
Nous voulons ici montrer que dans le cas des donnés que nous simulons, il y a égalité entre les deux coefficients suivants. \[\hat{\rho}^2 = \left(\frac{\sum_{i=1}^n (x_i - \bar{x})(y_i - \bar{y}) }{\sqrt{\sum_{i=1}^n (x_i - \bar{x})^2} \sqrt{\sum_{i=1}^n(y_i -\bar{y})^2}}\right)^2\]
\[\hat{\eta}^2 = \frac{\sum_{k=0}^1 n_k(\bar{x}_k - \bar{x})^2}{\sum_{i=1}^n (x_i - \bar{x})^2}\]
Nous pouvons déjà reconnaitre un terme en commun.
Pour des raisons de simplicité, on notera \(S_x^2 = \sum_{i=1}^n (x_i - \bar{x})^2\)
Nous pouvons alors manipuler un peu les termes de \(\hat{\rho}\)
\(\sum_{i=1}^n (x_i-\bar{x})(y_i - \bar{y})= \sum_{i=1}^n x_iy_i - n\bar{x}\bar{y}\)
et
\(\sum_{i=1}^n(y_i -\bar{y})^2= \sum_{i=1}^n y_i^2 - n\bar{y}^2\)
Maintenant, rappelons que dans notre cas précis, \(\forall i=1, ...,n\) où \(n=100\), \(y_i \sim \mathcal{B}(0.5)\). Nous pouvons donc supposer qu’idéalement on a une parfaite séparation en deux groupes avec autant de 0 que de 1. Et ainsi en déduire les simplifications suivantes :
\(\sum_{i=1}^n y_i^2 = \sum_{i=1}^n y_i\)
\(\bar{y} = \frac{n_1}{n}\)
\(\sum_{i=1}^n x_iy_i = n_1\bar{x}_1 \quad\) puisque l’on multipli par \(0\) les \(x_i\) associés au groupe \(0\)
Dès lors, nous avons \(\hat{\eta}^2 = \frac{n_0(\bar{x}_0 - \bar{x})^2 + n_1(\bar{x}_1 - \bar{x})^2}{S_x^2}\) et
\[\hat{\rho}^2 = \frac{1}{S_x^2} \times \frac{(n_1\bar{x}_1 - n_1\bar{x})^2}{n_1 - \frac{n_1^2}{n}}\] \[\quad = \frac{1}{S_x^2} \times \frac{n_1(\bar{x}_1 - \bar{x})^2}{1 - \frac{n_1}{n}}\] \[\quad = \frac{1}{S_x^2} \times \frac{n_1(\bar{x}_1 - \bar{x})^2}{\frac{n_0}{n}}\] \[\quad \quad = \frac{1}{S_x^2} \times \frac{n n_1(\bar{x}_1 - \bar{x})^2}{n_0}\]
Cela veut donc dire que l’on cherchera à montrer que
\[\frac{n n_1(\bar{x}_1 - \bar{x})^2}{n_0} = n_0(\bar{x}_0 - \bar{x})^2 + n_1(\bar{x}_1 - \bar{x})^2\]
\[\quad \quad \Leftrightarrow 1 = \frac{n_0^2(\bar{x}_0 - \bar{x})^2}{n n_1(\bar{x}_1 - \bar{x})^2} \times \frac{n_0}{n}\]
Mais si on suppose que \(y\) est “parfaitement équilibrée”, c’est à dire qu’il y aurait autant de 0 que de 1, on aura que \(n_0 = n_1 = \frac{n}{2}\) et aussi \[n\bar{x} = n_0\bar{x}_0 + n_1\bar{x}_1 \Leftrightarrow \bar{x} = \frac{1}{2}(\bar{x}_0 + \bar{x}_1) \Leftrightarrow \bar{x}-\bar{x}_0 = \bar{x}_1 - \bar{x}\]
Nous aurons donc que \((\bar{x}_0-\bar{x})^2 = (\bar{x}_1 - \bar{x})^2\)
Finalement, \[\frac{n_0^2(\bar{x}_0 - \bar{x})^2}{n n_1(\bar{x}_1 - \bar{x})^2} \times \frac{n_0}{n} = \frac{(\frac{n}{2})^2}{n (\frac{n}{2})} + \frac{(\frac{n}{2})}{n}\] \[\quad \quad \quad \quad \quad \quad = \frac{(\frac{n}{2})}{n} + \frac{(\frac{n}{2})}{n}\] \[\quad \quad \quad \quad \quad \quad = \frac{1}{2} + \frac{1}{2}\] \[\quad \quad \quad \quad \quad \quad= 1\]
Dans la situation que nous avons ici, nous pouvons donc conclure que \(\hat{\rho}^2 = \hat{\eta}^2\). On peut également supposer que cette égalité reste approximativement vrai dans des cas où “l’équilibre” n’est pas parfait.
A noter que dans la pratique, il convient généralement de vérifier que la variable réponse à suffisament de données et dans ces données, suffisament de \(1\) caractérisant le succès de l’événement. Ici, comme on est sur une génération de \(y\) par loi de bernouilli de paramètre \(0.5\) avec \(100\) individus et que nous retenons \(5\) variables explicatives, toutes les conditions semblent respectées.
keep_variables <- order(abs(cor_vect), decreasing=TRUE)[1:5]
Sub_Simu_data <- data.frame(cbind(y, x[,keep_variables]))
mod <- glm(y ~ ., data = Sub_Simu_data, family = 'binomial')
mod %>% summary()
Call:
glm(formula = y ~ ., family = "binomial", data = Sub_Simu_data)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.5826 0.2868 2.031 0.04223 *
V3530 -0.8820 0.2864 -3.079 0.00207 **
V2416 0.5686 0.2744 2.073 0.03821 *
V1512 1.0119 0.3180 3.182 0.00146 **
V1480 -0.4042 0.3044 -1.328 0.18417
V3875 0.9207 0.3254 2.830 0.00466 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 137.628 on 99 degrees of freedom
Residual deviance: 90.046 on 94 degrees of freedom
AIC: 102.05
Number of Fisher Scoring iterations: 5Résultats
On remarque que plusieurs variables du modèles sont significatives. Cela pourrait alors nous faire penser que notre modèle n’est pas mauvais pour expliquer \(y\) alors que pourtant nous étions censés n’avoir aucun lien entre les variables
Estimons maintenant le taux d’erreur de classification associé à ce modèle effectuant une validation croisée K-fold avec \(K = 10\).
err <- cv.glm(Sub_Simu_data, mod, cost, 10)$delta[1]
err[1] 0.25On peut remarquer une erreur faible de 0.25 alors que pourtant, comme dit plus haut et démontré, celle ci devrait se situer autour de 0.5. Cela peut donc déjà nous faire douter de notre démarche.
On va alors tenter de recommencer la même procédure 10 fois, obtenir 10 taux d’erreurs, et regarder la moyenne de ses taux.
res <- c()
Start_time <- Sys.time()
for (i in 1:10) {
cat(paste("->", i, "\n")) # counter to see progress
x <- matrix(rnorm(n*p, 0, 1), ncol = p) %>% as.data.frame()
cor_vect <- unlist(lapply(x, function(col) cor(col, y)))
keep_variables <- order(abs(cor_vect), decreasing = T)[1:5]
Sub_Simu_data <- data.frame(cbind(y, x[, keep_variables]))
mod <- glm(y ~ ., data = Sub_Simu_data, family = 'binomial')
res[i] <- cv.glm(Sub_Simu_data, mod, cost, 10)$delta[1]
}-> 1
-> 2
-> 3
-> 4
-> 5
-> 6
-> 7
-> 8
-> 9
-> 10 End_time <- Sys.time()
cat("Temps de calcul : ", End_time - Start_time, "s","\n" )Temps de calcul : 0.9272268 s res %>% summary() Min. 1st Qu. Median Mean 3rd Qu. Max.
0.1900 0.2025 0.2200 0.2250 0.2475 0.2600 Là aussi, le résultat est loin de tourner autour de 0.5. On a donc bien une erreur dans notre démarche.
Résultats
Ces résultats illustrent donc le problème du biais de sélection. En effet, lorsque l’on effectue la validation croisée, l’échantillon test n’est certes pas utilisé pour l’estimation du modèle, mais il a été utilisé initialement pour sélectionner les variables.
Ainsi lorsque nous confrontons les prévisions à l’échantillon test, ces dernières sont trop optimistes car elles ont déjà utilisé l’information contenue dans cet échantillon test.
Pour estimer convenablement le taux d’erreur, il faut que l’échantillon test ne soit utilisé à aucun moment dans la procédure de modélisation. La séparation de nos données expliquée dans la section précédente est donc cruciale.
On va cette fois ci corriger ce problème et répéter à nouveau la procédure 10 fois pour voir si on obtient des taux d’erreurs plus logiques.
res2 <- c()
Start_time <- Sys.time()
for (t in 1:10) {
cat(paste("->", t, "\n"))
x <- matrix(rnorm(n*p, 0, 1), ncol = p) %>% as.data.frame()
kf <- 10
seg <- pls::cvsegments(nrow(x), kf)
tmp <- c()
for (i in 1:kf) {
# We define our sample test
test <- seg[[i]]
cor_vect <- unlist(lapply(x, function(col) cor(col, y)))
keep_variables <- order(abs(cor_vect), decreasing = T)
Sub_Simu_data <- data.frame(cbind(y, x[, keep_variables[1:5]]))
mod <- glm(y ~ .,
data = Sub_Simu_data,
subset = -test,
family = 'binomial')
pred <- predict(mod, Sub_Simu_data[test, ], type = "response")
tmp[i] <- cost(y[test], pred)
}
res2[t] <- mean(tmp)
}-> 1
-> 2
-> 3
-> 4
-> 5
-> 6
-> 7
-> 8
-> 9
-> 10 End_time <- Sys.time()
cat("Temps de calcul : ", End_time - Start_time, "s", "\n" )Temps de calcul : 5.924056 s res2 %>% summary() Min. 1st Qu. Median Mean 3rd Qu. Max.
0.1900 0.2000 0.2200 0.2190 0.2375 0.2500 On retrouve enfin des taux d’erreurs plus cohérents qui sont en moyenne à 0.219. Par contre on remarque que le temps de calcul à cette fois ci été plus important. Cela prouve bien que faire choses biens ca prend du temps.
Dans cette partie, nous allons nous intéresser au problème des corrélations fortuites qui apparaissent très souvent dans les jeu de données de grande dimension.
Pour cela, nous pouvons revenir d’abord sur le fait que notre modèle calculé précédemment possédait toutes ses variables significatives au niveau \(\alpha = 5\%\). Et elles semblent aussi être corrélées à \(y\), d’après la valeur de \(\hat{\rho}\), alors qu’elles sont censées être indépendantes de \(y\).
D’après le théorème limite central, nous pouvons déjà admettre que la corrélation de Pearson \(\hat{\rho}\) entre deux variables non-corrélées suit approximativement, lorsque \(n\) est grand, une loi Normale centrée de variance \(\frac{1}{n}\) (explications plus détaillées en Preuve). À partir de cela, nous pouvons considérer que deux variables ont une corrélation significativement non nulle a seuil \(\alpha=5\%\) à partir de \(|\hat{\rho}|>q(1-\frac{\alpha}{2})\) avec \(q(1-\frac{\alpha}{2})\) le quantile d’une loi Normale centrée de variance \(\frac{1}{n}\).
Ici, nous souhaitons montrer que le \(\hat{\rho}\) de Pearson tend vers une loi normale centrée avec une variance \(\frac{1}{n}\) dans le cas où les variables ne sont pas corrélées.
On commence par noter
\(S_x = \sqrt{\sum_{i=1}^n (x_i - \bar{x})^2}\)
\(S_y = \sqrt{\sum_{i=1}^n (y_i - \bar{y})^2}\)
C’est valeurs représentent les écarts type. Ainsi, on a
\[\hat{\rho} = \frac{\sum_{i=1}^n (x_i - \bar{x})(y_i - \bar{y}) }{S_x S_y}\]
\[\quad \quad =\sum_{i=1}^n \frac{(x_i - \bar{x})}{S_x} \frac{(y_i - \bar{y})}{S_y}\]
Dans notre cas, nous avons nos \(x_i\) et \(y_i\) qui suivent des lois connues dans \(L^2\). Nous pouvons aussi remarquer que \(\mathbb{E}(\hat{\rho})=0\). Donc si nous supposons l’indépendance entre nos variables, nous pourrons appliquer le Théorème central limite.
\[\sqrt{n}(\hat{\rho} - \mathbb{E}(\hat{\rho})) = \sqrt{n}\hat{\rho} \overset{loi}{\underset{n\to+\infty}{\longrightarrow}} \mathcal{N}_{(0,\tau^2)}\]
où \(\tau^2\) représente la variance de \(\hat{\rho}\) quand n grand
Maintenant nous savons également que, si nos variables ne sont pas corrélées, \(\hat{\rho}=0\). Il est donc possible de déduire que plus \(n\) sera grand avec des variables non corrélées, plus la variance va être proche de 0. Nous avons donc bien que \(\hat{\rho}\underset{\text{$n$ grand}}{\sim}\mathcal{N}_{(0,\frac{1}{n})}\)
Ainsi, en comparant les corrélations des variables que l’on a retenu dans le modèle logistique précédent avec ce seuil, nous obtenons que les cinq variables du modèle ont une corrélation supérieure à ce quantile. Ce qui veut dire que ces variables ont une corrélation avec \(y\) significativement non nulle au seuil \(\alpha=5\%\).
y <- rbinom(n, 1, 0.5)
x <- matrix(rnorm(n*p, 0, 1), ncol = p) %>% as.data.frame()
cor_vect <- unlist(lapply(x, function(col) cor(col, y)))
quant <- qnorm(0.975, 0, 1/10)
mod_variables <- order(abs(cor_vect), decreasing = T)[1:5]
Nb_ModVar_quantile_sup <- sum((abs(cor_vect[mod_variables])) > quant)Pour les 5, variables de notre modèles on a 5 variables qui ont une corrélation supérieure à notre quantile
Et regardons ce qui se passe si nous prenons toutes nos variables pour comparer leur corrélation à notre quantile.
Nb_Var_quantile_sup <- sum((abs(cor_vect)) > quant)On a que 240 variables sur les 5000 (donc environ 4.8% de nos variables) ont une corrélation avec \(y\) significativement non nulle au seuil \(\alpha=5\%\).
Résultats
Nous avons donc ici une parfaite illustration du phénomène de corrélations fortuites. Plus précisément, les corrélations empiriques précédentes sont appelées “faux positifs” : elles semblent significatives alors qu’en théorie aucune corrélation n’existe.
Ce phénomène est propre à la grande dimension et nous montre qu’à force de chercher des corrélations parmi un grand nombre de variables, nous en trouvons toujours. Cela à cause des fluctuations de la corrélation empirique et même si aucune corrélation théorique n’existe.
La validation croisée, correctement appliquée, permet ainsi de détecter ce phénomène.
En conclusion, avec cette étude nous avons pu illustrer deux grands problèmes que nous pouvons observer dans le cas de la Statistique en grande dimension.
Nous avons le biais de sélection qui arrive lorsque l’on utilise notre échantillon test dans la sélection de variable ou l’ajustement du modèle. Et donc quand on confronte nos prévisions à l’échantillon test, ces dernières seront beaucoup trop optimistes. C’est pour ca que la séparation de notre échantillon doit être faite avant la sélection de nos variables.
Puis, il y a la corrélation fortuite qui est propre à la grande dimension et qui nous montre qu’il faut bien connaître nos données. Lorsque l’on veut construire un modèle, il faut déjà avoir une connaissance sur les variables qui peuvent être liées. Et si on cherche des corrélation sur un jeu de grande dimension, on risque probablement d’en trouver même si théoriquement il n’y en à pas.
Nous voyons donc qu’il faut comprendre les données sur lesquelles nous travaillons et même si les ordinateurs sont des outils performants, il faut que le statisticien garde toujours un regard critique sur les résultats.
sessioninfo::session_info(pkgs = "attached")─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.4.2 (2024-10-31)
os Ubuntu 24.04.1 LTS
system x86_64, linux-gnu
ui X11
language (EN)
collate fr_FR.UTF-8
ctype fr_FR.UTF-8
tz Europe/Paris
date 2025-02-21
pandoc 3.2 @ /usr/lib/rstudio/resources/app/bin/quarto/bin/tools/x86_64/ (via rmarkdown)
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
boot * 1.3-31 2024-08-28 [4] CRAN (R 4.3.3)
dplyr * 1.1.4 2023-11-17 [1] CRAN (R 4.4.2)
ggplot2 * 3.5.1 2024-04-23 [1] CRAN (R 4.4.2)
[1] /home/clement/R/x86_64-pc-linux-gnu-library/4.4
[2] /usr/local/lib/R/site-library
[3] /usr/lib/R/site-library
[4] /usr/lib/R/library
──────────────────────────────────────────────────────────────────────────────