Show the code
# Données
library(dplyr) ## Manipulation des données
# Inférence
library(boot) ## CV
# Esthétique
library(ggplot2) ## ggplot# Données
library(dplyr) ## Manipulation des données
# Inférence
library(boot) ## CV
# Esthétique
library(ggplot2) ## ggplotmy_boxplot <- function(data) {
# Transformer les données en format long pour ggplot
data_long <- reshape2::melt(data)
ggplot(data_long, aes(x = variable, y = value, fill = variable)) +
geom_boxplot() +
scale_fill_viridis_d() + # Palette de couleurs harmonieuse
labs(title = "Distribution des Variables (Boxplot)", x = "Variables", y = "Valeurs") +
theme_minimal() + # Thème épuré
theme(axis.text.x = element_text(angle = 45, hjust = 1)) # Rotation des étiquettes
}my_pairs.panels <- function(data) {
psych::pairs.panels(
data,
method = "pearson",
# Méthode de corrélation
hist.col = RColorBrewer::brewer.pal(9, "Set3"),
# Couleurs des histogrammes
density = TRUE,
# Ajout des courbes de densité
ellipses = TRUE,
# Ajout d'ellipses
smooth = TRUE,
# Ajout de régressions lissées
lm = TRUE,
# Ajout des droites de régression
col = "#69b3a2",
# Couleur des points
alpha = 0.5 # Transparence
)
}Première fonction LOO
loo <- function(mod) {
n <- nrow(mod$model)
Call <- mod$call
erreur <- 1:n
for (i in 1:n) {
Call$data <- mod$model[-i, ] # mod$call$data transforme en data.frame
fit <- eval.parent(Call)
pred = predict(fit, mod$model[i, ])
erreur[i] <- (pred - mod$model[i, 1])^2
}
return(round(mean(erreur), 3))
}Deuxième fonction LOO
loo2 <- function(mod) {
round(mean((residuals(mod) / (1 - hatvalues(mod)))^2), 3)
}Fonction pour obtenir les résultats
get_loo_results <- function(model, func) {
start_time <- Sys.time()
result <- func(model)
end_time <- Sys.time()
time_taken <- round(end_time - start_time, 3)
return(list(result = result, time = time_taken))
}set.seed(140400)Pour cette exercice, on va générer un modèle de régression linéaire classique :
\[y = X\beta + \mathcal{E}\]
\(y \in \mathbb{R}^{n}\) la variable réponse ou variable à expliquer
\(X \in \mathbb{R}^{n\times p}\) la matrice contenant nos variables explicatives
\(\beta \in \mathbb{R}^{p}\) le vecteur composée des coefficients de régression
\(\mathcal{E} \in \mathbb{R}^{n}\) le vecteur d’erreur suivant une loi \(\mathcal{N}(0, 1)\)
Pour la génération de nos données, nous allons alors poser que \(\beta = (1, -2)'\) et \(X = [x, x^2]\), \(x \in \mathbb{R}^n\) suivant une loi \(\mathcal{N}(0,1)\).
On aura alors que \(y = x - 2x^2 + \mathcal{E}\).
x <- rnorm(1000)
y <- x - 2*(x^2) + rnorm(1000)
Simu_data <- data.frame(y = y, x = x)pour des raisons de repouctibilité, une graine ou seed a été défini dans la partie Setup afin que la génération aléatoire reste identique.
On va ainsi supposer avoir observé les deux vecteurs \(x\) et \(y\) précédents, sans connaître le lien théorique précédent qui lie \(x\) et \(y\).
Et donc on cherchera à estimer ce lien.
On peut regarder un peu la distribution de nos différents variables quantitatives via des boxplots.
my_boxplot(Simu_data)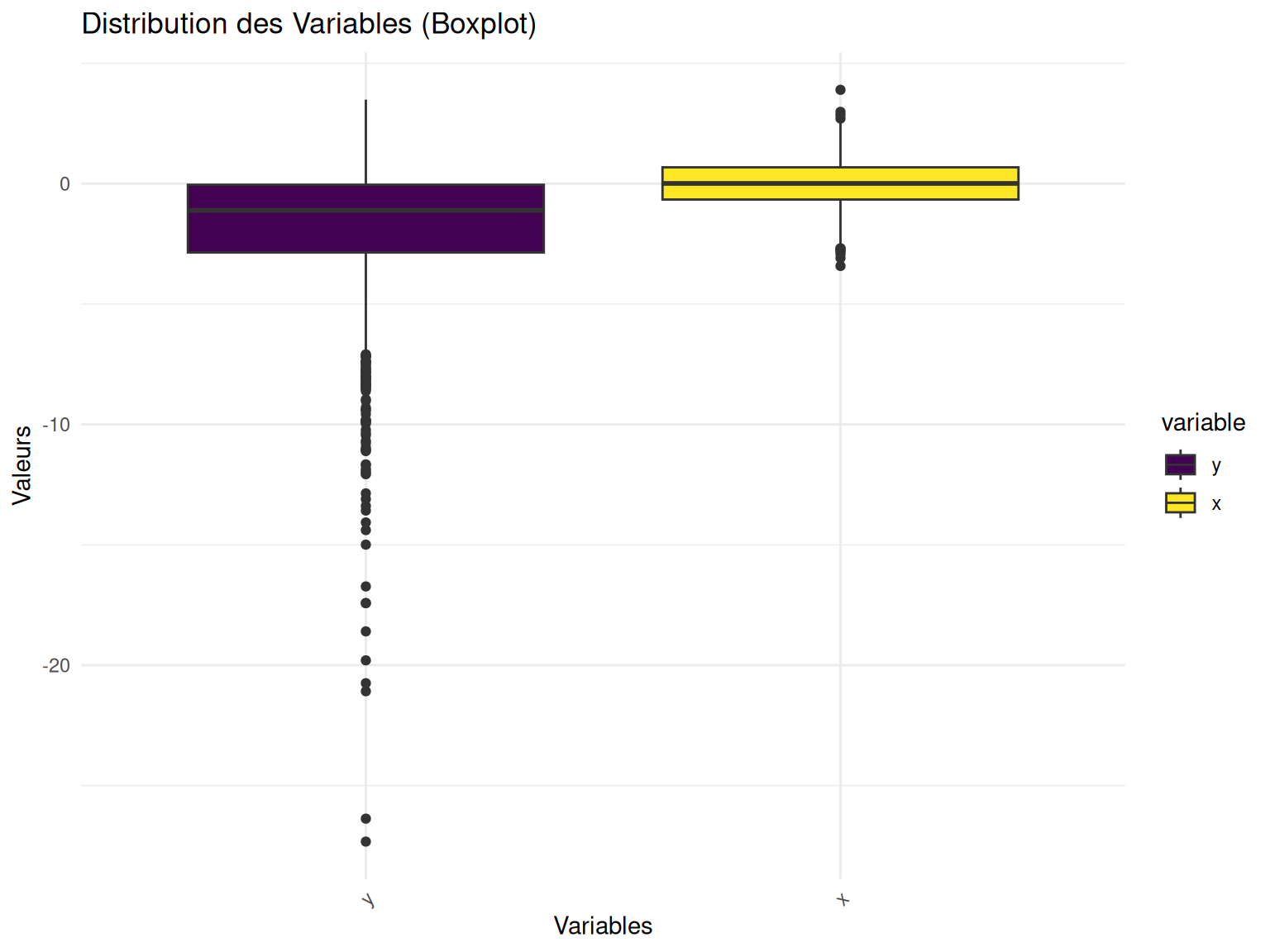
Résultats
On voit bien que notre variable \(x\) a une distribution normale centré réduite mais quelle n’est pas non plus parfaitement symétrique (forcément entre la “perfection” de la théorie et la génération par ordinateur il y a toujours une légère différence).
Et concernant \(y\), de manière logique avec le modèle simulé, on peut voir d’avantages de valeurs négatives.
On regarde ici la corrélation calculée entre chacune de nos variables.
my_pairs.panels(Simu_data)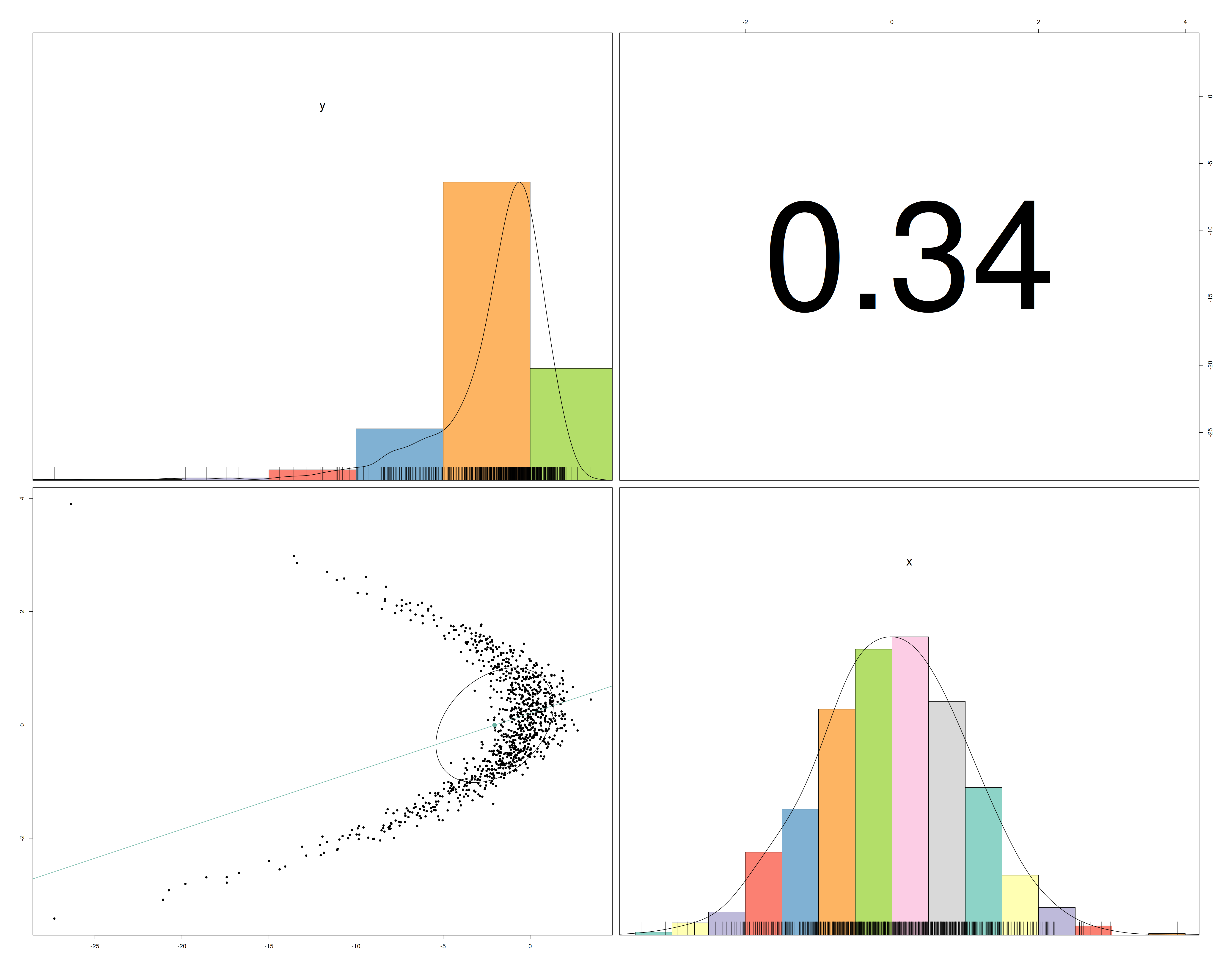
Résultats
Tout d’abord, on peut remarquer une corrélation faible de 34% entre \(x\) et \(y\). Pourtant le nuage de point semble quand à lui témoigner d’une influence de \(x\) sur \(y\) pouvant justifier d’un lien linéaire.
Aussi on retrouve un belle histogramme de distibution \(\mathcal{N}(0, 1)\) pour notre variable \(x\).
Maintenant, on va ajuster différents modèles à tester :
mod1 : \(y = \beta_0 + \beta_1x + \mathcal{E}\)
mod2 : \(y = \beta_0 + \beta_1x + \beta_2x^2 + \mathcal{E}\)
mod3 : \(y = \beta_0 + \beta_1x + \beta_2x^2 + \beta_3x^3 + \mathcal{E}\)
mod4 : \(y = \beta_0 + \beta_1x + \beta_2x^2 + \beta_3x^3 + \beta_4x^4 + \mathcal{E}\)
On va donc commencer par compléter notre data frame avec des variables correspondant à \(x^2\), \(x^3\) et \(x^4\). Puis nous pourrons ajuster les différents modèles.
Simu_data_complete <- cbind(Simu_data, x^2, x^3, x^4)
colnames(Simu_data_complete) <- c("y", "x1", "x2", "x3", "x4")mod1 <- lm(y ~ x1, Simu_data_complete)
mod2 <- lm(y ~ x1 + x2, Simu_data_complete)
mod3 <- lm(y ~ x1 + x2 + x3, Simu_data_complete)
mod4 <- lm(y ~ x1 + x2 + x3 + x4, Simu_data_complete)Théoriquement, on est dans une situation où le coefficient de détermination \(R^2\) pour le modèle 1 est égale à la corrélation de pearson au carré de \(x\) et \(y\). On peut le constater en récupérant les différentes valeurs obtenues à partir du summary du modèle 1 et la fonction cor :
\(R^2 =\) 0.116
\(\rho^2 =\) 0.116
On commence par poser quelques notations usuelles :
\(S_{XY} = \sum_i (x_i - \bar{x})(y_i - \bar{y})\)
\(S_{XX} = \sum_i (x_i - \bar{x})^2 \quad \text{et} \quad S_{YY} = \sum_i (y_i - \bar{y})^2\)
Ainsi on peut définir avec ces notations le coefficient de détermination et la corrélation de pearson.
\[R^2 = 1 - \frac{\sum_i (y_i - \hat{y_i})^2}{S_{YY}}\quad \text{et} \quad \rho = \frac{S_{XY}}{\sqrt{S_{XX}S_{YY}}}\]
On rappel aussi que pour le modèle simple de resgression linéaire \(y=\beta_0 + \beta_1x + \varepsilon\), l’estimation de nos coefficients de régression nous donne que \(\hat{\beta_0} = \bar{y} - \hat{\beta_1}\bar{x}\) et \(\hat{\beta_1} = \frac{S_{XY}}{S_{XX}}\).
On peut alors commencer à jouer avec ces formules pour retrouver l’égalité dans le cas du modèle 1. \[\begin{align*}
\sum_i (y_i - \hat{y_i})^2 &= \sum_i (y_i - (\hat{\beta_0} + \hat{\beta_1}x))^2\\
&= \sum_i (y_i - (\bar{y} - \hat{\beta_1}\bar{x} + \hat{\beta_1}x_i))^2\\
&= \sum_i ((y_i - \bar{y}) - \hat{\beta_1}(x_i - \bar{x}))^2\\
&= \sum_i (y_i - \bar{y})^2 + \hat{\beta_1}^2\sum_i(x_i - \bar{x})^2 - 2\hat{\beta_1}\sum_i(y_i - \bar{y})(x_i - \bar{x})\\
&= S_{YY} + \hat{\beta_1}^2S_{XX} - 2\hat{\beta_1}S_{XY}\\
&= S_{YY} + \left(\frac{S_{XY}}{S_{XX}}\right)^2S_{XX} - 2\frac{S_{XY}}{S_{XX}}S_{XY}\\
&= S_{YY} + \frac{S_{XY}^2}{S_{XX}} - 2\frac{S_{XY}^2}{S_{XX}}\\
&= S_{YY} - \frac{S_{XY}^2}{S_{XX}}\\
&= S_{YY} \left( 1 - \frac{S_{XY}^2}{S_{YY}S_{XX}} \right)\\
&= S_{YY}(1 - \rho^2)\\
\end{align*}\]
Et donc on a la relation \(R^2 = 1 - \frac{S_{YY}(1 - \rho^2)}{S_{YY}} = 1 - (1 - \rho^2) = \rho^2\)
Ensuite, partir du summary et de différentes fonctions R, on est capable capable d’obtenir différents critères permettant de comparer la qualité de nos modèles.
models <- list(mod1, mod2, mod3, mod4)
model_names <- c("mod1", "mod2", "mod3", "mod4")
results <- data.frame(
Model = model_names,
R2 = unlist(lapply(models, function(m) round(summary(m)$r.squared, 3))),
R2adj = unlist(lapply(models, function(m) round(summary(m)$adj.r.squared, 3))),
AIC = unlist(lapply(models, function(m) round(AIC(m), 1))),
BIC = unlist(lapply(models, function(m) round(BIC(m), 1)))
)
results %>% DT::datatable()On peut voir ici que c’est mod2 qui ressort comme étant le meilleur modèle avec de forte valeur de \(R^2\) et \(R^2_{adjusted}\) puis des critères AIC et BIC minimisés.
mod2 %>% summary()
Call:
lm(formula = y ~ x1 + x2, data = Simu_data_complete)
Residuals:
Min 1Q Median 3Q Max
-3.1117 -0.7078 -0.0106 0.6605 3.3936
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.03778 0.03820 0.989 0.323
x1 1.02939 0.03105 33.151 <2e-16 ***
x2 -2.01737 0.02107 -95.725 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.995 on 997 degrees of freedom
Multiple R-squared: 0.9133, Adjusted R-squared: 0.9131
F-statistic: 5248 on 2 and 997 DF, p-value: < 2.2e-16On constate en plus avec le summary que toutes nos variables sont significatives sauf l’intercept.
Le principe de la validation croisée (cross validation) est d’estimer le risque de prédiction en confrontant notre modèle à un échantillon test qui n’a pas été utilisé pour l’ajustement de celui ci.
La validation croisée possède ainsi de nombreux avantages mais a comme principal inconvénient son temps de calcul qui peut rapidement devenir important.
Dans le cas du K-fold, on coupe l’échantillon de taille \(n\) en environ K parties égales. Ensuite, on fait l’ajustement du modèle sur K-1 échantillons et on garde le K-ième comme échantillon test pour calculer l’erreur de prédiction. On répète alors le procédé de telle sorte à ce que chaque échantillon serve une fois de test. Cela nous fait donc calculer K erreurs.
A savoir que selon la valeur de K, on peut se retrouver dans des cas particuliers très utilisés.
Lorsque K = n, il s’agit de la procédure Leave One Out (LOO).
Lorsque K = 2, on est sur une procédure Hold out ou testset
La validation croisée par K-fold est donc un outil couramment utilisé. Le choix de K est quant à lui très important et il faut penser que si K est trop grand, le biais sera faible mais à contrario, la variance deviendra très grande. Par contre, si K est trop petit, l’estimation risque de posséder un grand biais puisque notre taille d’échantillon test sera beaucoup plus grande que celle de l’échantillon d’apprentissage. On a donc ici un bel exemple de compromis entre biais et variance pour trouver le K le plus judicieux.
Dans un premier temps et pour bien comprendre la méthode, on va utiliser deux fonctions (construite pour l’occasion et dont le code se trouve dans la partie fonction du Setup) permettant d’estimer l’erreur test par une validation croisée LOO (Leave-one-out) pour un modèle ajusté par la fonction lm :
la première, loo, en utilisant le principe général de cette méthode qui nécessite donc l’estimation de n modèles différents
la seconde, loo2, en utilisant la formule adaptée à la régression linéaire donnant directement le risque LOO à partir de la seule estimation du modèle complet (on pourra utiliser la fonction hatvalues)
Ainsi, en testant sur nos quatre modèle, on obtient les résultats suivants :
loo_results <- lapply(models, function(m) get_loo_results(m, loo))
loo2_results <- lapply(models, function(m) get_loo_results(m, loo2))
results <- data.frame(
Model = model_names,
LOO = unlist(lapply(loo_results, function(x) x$result)),
Time_LOO = unlist(lapply(loo_results, function(x) x$time)),
LOO2 = unlist(lapply(loo2_results, function(x) x$result)),
Time_LOO2 = unlist(lapply(loo2_results, function(x) x$time))
)
results %>% DT::datatable()Résultats
On voit que les résultats donnés par nos deux fonctions coincident bien. Mais la première semble tout de même plus lente pour le calcul.
Et en terme de qualité de modèle, c’est bien mod2 qui minimise l’erreur de la cross validation par loo.
On va donc maintenant utiliser la fonction cv.glm de la library {boot} permettant d’estimer l’erreur test par validation croisée K-fold. Cela va nécessité de recalculer le modèle mais cette fois ci avec la fonction glm en spécifiant que l’on veut un modèle gaussien (ce qui nous donnera le même résultat qu’avec lm).
On spécifi ici dans glm que le modèle est gaussien mais dans la pratique ce n’est pas nécéssaire pusiqu’il s’agit de la valeur par défaut de la fonction.
De plus, nous utiliserons \(K=10\) qui est une valeurs assez communément utilisé sachant que si on voulait reproduire la procédure LOO il faudrait utiliser \(K=n \quad\) (cf rappel).
mod1_glm <- glm(formula = formula(mod1) ,
family = gaussian,
data = Simu_data_complete)
mod2_glm <- glm(formula = formula(mod2) ,
family = gaussian,
data = Simu_data_complete)
mod3_glm <- glm(formula = formula(mod3) ,
family = gaussian,
data = Simu_data_complete)
mod4_glm <- glm(formula = formula(mod4) ,
family = gaussian,
data = Simu_data_complete)
cvmod1 <- cv.glm(data = Simu_data_complete, glmfit = mod1_glm, K = 10)
cvmod2 <- cv.glm(data = Simu_data_complete, glmfit = mod2_glm, K = 10)
cvmod3 <- cv.glm(data = Simu_data_complete, glmfit = mod3_glm, K = 10)
cvmod4 <- cv.glm(data = Simu_data_complete, glmfit = mod4_glm, K = 10)
results <- data.frame(
Model = model_names,
CV_Mean = round( c(mean(cvmod1$delta), mean(cvmod2$delta), mean(cvmod3$delta), mean(cvmod4$delta)), 3),
LOO2 = c(loo2(mod1), loo2(mod2), loo2(mod3), loo2(mod4))
)
results %>% DT::datatable()Résultats
On voit qu’en moyenne cv.glm nous donne des résultats qui sont du même ordre de grandeur que notre fonction loo2.
Et en terme de qualité de modèle, c’est bien mod2 qui minimise l’erreur de la cross validation.
D’après tout ce que l’on a pu voir durant cette étude, jusqu’à présent le meilleur modèle semble être mod2.
mod2 %>% summary()
Call:
lm(formula = y ~ x1 + x2, data = Simu_data_complete)
Residuals:
Min 1Q Median 3Q Max
-3.1117 -0.7078 -0.0106 0.6605 3.3936
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.03778 0.03820 0.989 0.323
x1 1.02939 0.03105 33.151 <2e-16 ***
x2 -2.01737 0.02107 -95.725 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.995 on 997 degrees of freedom
Multiple R-squared: 0.9133, Adjusted R-squared: 0.9131
F-statistic: 5248 on 2 and 997 DF, p-value: < 2.2e-16De manière naturelle, l’intercept ne semblant pas significatif il conviendrait de tester sans.
Ainsi nous allons essayer le modèle \(y \sim x + x^2\).
mod2_without_intercept <- lm(y ~ 0 + x1 + x2, Simu_data_complete)
mod2_without_intercept %>% summary()
Call:
lm(formula = y ~ 0 + x1 + x2, data = Simu_data_complete)
Residuals:
Min 1Q Median 3Q Max
-3.0785 -0.6834 0.0212 0.6855 3.4288
Coefficients:
Estimate Std. Error t value Pr(>|t|)
x1 1.02988 0.03105 33.17 <2e-16 ***
x2 -2.00555 0.01736 -115.54 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.995 on 998 degrees of freedom
Multiple R-squared: 0.9364, Adjusted R-squared: 0.9363
F-statistic: 7352 on 2 and 998 DF, p-value: < 2.2e-16On voit un modèle avec de très bon résultats et qui à toutes ces variables significatives. Comparons le avec mod2 :
models <- list(mod2, mod2_without_intercept)
model_names <- c("mod2", "mod2_without_intercept")
results <- data.frame(
Model = model_names,
R2 = unlist(lapply(models, function(m)
round(summary(m)$r.squared, 3))),
R2adj = unlist(lapply(models, function(m)
round(summary(m)$adj.r.squared, 3))),
AIC = unlist(lapply(models, function(m)
round(AIC(
m
), 1))),
BIC = unlist(lapply(models, function(m)
round(BIC(
m
), 1))),
LOO2 = c(loo2(mod2), loo2(mod2_without_intercept)),
CV_Mean = round(c(
mean(cv.glm(
data = Simu_data_complete,
glmfit = glm(
formula = formula(mod2),
data = Simu_data_complete
),
K = 10
)$delta), mean(cv.glm(
data = Simu_data_complete,
glmfit = glm(
formula = formula(mod2_without_intercept),
data = Simu_data_complete
),
K = 10
)$delta)
), 3)
)
results %>% DT::datatable()Résultats
On voit bien avec tout nos critère qu’enlever l’intercept à apporté une amélioration à notre modèle.
Ainsi, si l’on se base sur les résultat de ce nouveau modèle, on obtient la relation linéaire suivante :
Alors que pour rappel, on a le lien linéaire théorique qui est:
Donc je pense que l’on peut dire sans prendre trop de risques que notre estimation et notre méthode de sélection est bonne.
On voit qu’on a bien réussi à retrouver le lien théorique via le test de pluseurs modèle et l’utilisation de plusieurs critères couplés à de la validation croisée pour affiner notre recherche du modèle le mieux ajusté.
Ainsi, il est important d’avancer étape par étape car ici chaques étapes était importante pour trouver le meilleur modèle. Et ici on se basait sur un modèle généré par nous même et possédant un lien linéaire bien défini ce qui nous permettait tout de même si bien orienter nos recherche. La réalité nous offre souvent des situations plus compliquées et tout ces outils deviennent donc cruciaux pour bien avancer.
sessioninfo::session_info(pkgs = "attached")─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.4.2 (2024-10-31)
os Ubuntu 24.04.1 LTS
system x86_64, linux-gnu
ui X11
language (EN)
collate fr_FR.UTF-8
ctype fr_FR.UTF-8
tz Europe/Paris
date 2025-03-03
pandoc 3.2 @ /usr/lib/rstudio/resources/app/bin/quarto/bin/tools/x86_64/ (via rmarkdown)
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
boot * 1.3-31 2024-08-28 [4] CRAN (R 4.3.3)
dplyr * 1.1.4 2023-11-17 [1] CRAN (R 4.4.2)
ggplot2 * 3.5.1 2024-04-23 [1] CRAN (R 4.4.2)
[1] /home/clement/R/x86_64-pc-linux-gnu-library/4.4
[2] /usr/local/lib/R/site-library
[3] /usr/lib/R/site-library
[4] /usr/lib/R/library
──────────────────────────────────────────────────────────────────────────────